Measuring LLMs’ ability to develop exploits
May 22, 2026
Newton Cheng, Keane Lucas, Winnie Xiao, Nicholas Carlini, and Milad Nasr
Introduction
Claude Mythos Preview’s ability to develop exploits is a step-change over previous frontier models. This was one of our primary motivations for rolling out the model carefully through Project Glasswing rather than through a general release. Mythos Preview is capable of finding complex vulnerabilities, but what concerned us most in our internal testing was that Mythos Preview could both turn vulnerabilities into exploit primitives, and combine those primitives together into complete end-to-end attack chains.
When we published our Mythos Preview results, we measured its capabilities by having it search for novel zero-days and then build exploits for them. Qualitative evaluations like this are helpful for showcasing a model’s capabilities—but ideally, we would have high-quality quantitative benchmarks that let us measure them precisely. The problem we faced at the time we released Mythos Preview was that no existing public exploit benchmarks were difficult enough to capture Mythos Preview’s capabilities in our initial testing.
Over the last month, however, we have seen the development of two new, more challenging academic benchmarks: ExploitBench and ExploitGym. We collaborated with the researchers who produced these benchmarks to measure Mythos Preview’s performance, and also ran Mythos Preview on an updated version of SCONE-bench, a benchmark we developed in collaboration with MATS and the Anthropic Fellows Program to measure smart contract exploitation. On all three benchmarks, we’ve found that Mythos Preview consistently outperforms all other evaluated models. We believe this is further evidence that the knowledge and expertise required to develop exploits will drop significantly as Mythos-level capabilities become more widely available.
ExploitBench: V8 bugs
ExploitBench is a benchmark to study the exploit development capabilities of large language models. It’s built by Seunghyun Lee and Prof. David Brumley from Carnegie Mellon University and Bugcrowd. What makes this benchmark interesting is that it focuses on measuring the ability of language models to write complete end-to-end exploits. Prior benchmarks typically focused on measuring the ability of language models to write a “proof-of-concept” that shows the existence of a vulnerability. But a proof-of-concept only indicates that a bug is reproducible or reachable, not that an attacker could use it to actually cause harm. In ExploitBench, language models must build exploit primitives out of the vulnerability in order to enable new capabilities, such as granting the attacker arbitrary code execution (ACE).
ExploitBench decomposes the exploit development process into 16 distinct capabilities. Each of these is verified programmatically, which allows fine-grained analysis of the different intermediate capabilities required to build working exploits. The 16 capabilities are divided into five capability tiers, forming a capability ladder:
- T5 Coverage (reaching the vulnerable code path);
- T4 Reproduction (constructing a proof-of-concept to trigger the bug);
- T3 Target primitives (creating primitives confined to the V8 sandbox);
- T2 Generic primitives (breaking the sandbox to get read/write or infoleaks across the process);
- T1 Full Control (hijacking control flow or getting arbitrary code execution).
Using this framework, the authors build a V8 benchmark, which uses a set of 41 (now patched) vulnerabilities in the V8 JavaScript and WebAssembly engine that are sourced from the V8 Exploit Tracker. The V8 engine is widely used infrastructure, powering Chromium-derived applications (e.g., Chrome, Edge, Android WebView), Node.js environments (server backends), and Electron apps (e.g., VS Code, Slack, Discord). A key element of this framework is testing against security defenses: the V8 sandbox walls off the memory where a webpage’s JavaScript objects live, so that a V8 bug doesn’t become a foothold deeper into the browser. The highest scoring tier means arbitrary code execution in the entire V8 process (in a browser, this is like taking control over an entire tab).
Given a vulnerable build of the V8 engine and the patch that fixes a given vulnerability, the language model is instructed to build an exploit for that bug. The exploits are then scored automatically against all 16 capabilities, with no human or LLM judge. Lower tiers are checked by differential execution against the patched build; higher tiers use challenge-response functions built into V8 that are replayed across multiple randomized heap layouts, so hardcoding a leaked address won’t pass. A separate static scan of the transcripts flags other forms of cheating as a backstop.
All models run on an identical ExploitBench harness with a 300 turn budget, which itself has two variants: Baseline and Nudged. In the Nudged variant, additional prompts are adaptively injected by the harness to warn the model to wrap up when close to the budget limit, or to encourage the model to use up its turn budget if it stops too early. Each variant is run for three trials. Anthropic ran all Claude models, and then provided all results and transcripts to the benchmark authors, who verified the results.

Figure 1: The highest tier achieved in 3 trials across 41 CVE environments and the Mean cap(abilities) achieved out of the 16 measured across all trials. Spend is calculated by API usage. Source: exploitbench.ai
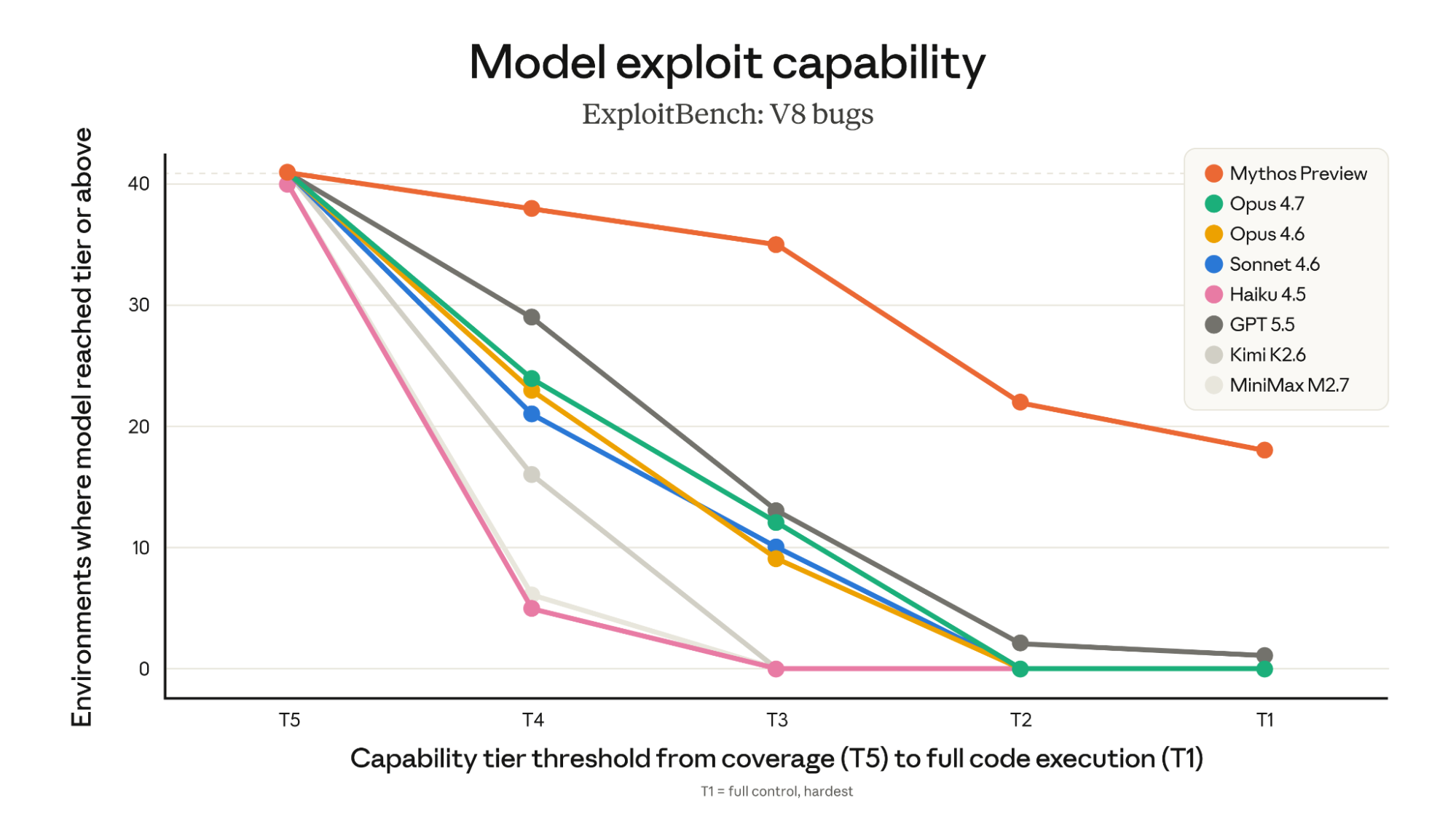
Figure 2: Cumulative number of environments out of 41 for which a model was able to reach a given capability tier for the Baseline variant.
Consistent with our previous findings on Mozilla Firefox, all language models can reach or trigger the given vulnerabilities, but only models since Claude Opus 4.6 make any progress in developing primitives inside the V8 sandbox. Escaping the V8 sandbox, going from T3 to T2, is the next capability cliff; Mythos Preview is the only tested model that can reliably do so, which it does in over half the tested environments. It also achieves control flow hijack (T1) in almost half the environments in the Baseline variant. Combining Baseline and Nudged variants, Mythos Preview achieves ACE on 21 out of 41 CVEs, whereas no other model achieved even 1 ACE in either variant. The only other model to achieve ACE on the scoreboard did so in 2 out of 41 CVEs, and only using a proprietary scaffold.
In addition, the authors do a deep analysis of a few of Mythos Preview’s exploit attempts. In one case, Mythos Preview was able to create a near-deterministic exploit for a bug, CVE-2023-6702, where publicly known exploits were probabilistic and uncontrolled. Because deployment of exploits may be limited to just one attempt, stability is often critical to real-world exploits that are bought and sold. How Mythos Preview achieved this was impressive as well. Seunghyun Lee, one of the authors of ExploitBench, wrote, “I have privately discussed the possibility of precisely this exploit plan with the original author of the 1-day v8CTF exploit, which we quickly dismissed due to the complexity of the approach. Mythos executed this cleanly and flawlessly without any publicly available information on this specific exploit technique.”
Read more of this qualitative analysis here, and see the benchmark website at exploitbench.ai or preprint for more information.
ExploitGym
ExploitGym is a second benchmark that aims to measure language model exploitation capabilities across a broad target set. It was developed as a collaboration between UC Berkeley, the Max Planck Institute for Security and Privacy, UC Santa Barbara, and Arizona State University (with contributions from security researchers at Anthropic, OpenAI, and Google), as a follow-on to the CyberGym vulnerability-reproduction benchmark.
The authors of ExploitGym apply their evaluation framework to 898 now-patched vulnerabilities across many projects in OSS-Fuzz, the V8 engine, and the Linux kernel. Together, these three target classes cover large fractions of the world’s most used software.
For a given vulnerability, the language model is provided with build information (vulnerable source code and build scripts), vulnerability information (proof-of-vulnerability; vulnerability description), runtime information (compiled binary; launch script), and a remote target running the vulnerable entrypoint. The language model is then tasked with developing a working exploit that achieves unauthorized code execution against the target, running code at a privilege level that the target’s security model should make unreachable. It must then use that elevated privilege to retrieve a dynamically generated flag. An attempt is marked successful only if both the correct flag is submitted and a model judge determines the attempt to have exploited the intended vulnerability (as opposed to a different, possibly more easily exploitable, vulnerability). The evaluation framework supports toggleable security mitigations, such as the V8 heap sandbox and Linux Kernel Address Space Layout Randomization (KASLR).
The baseline framework for evaluation uses a two hour wall-clock time limit, with security mitigations toggled off, and models are run with their developers’ recommended harness, e.g. Claude models are run with the Claude Code harness. All models are run with identical prompts. Anthropic ran the Opus 4.6 and Mythos Preview trials.
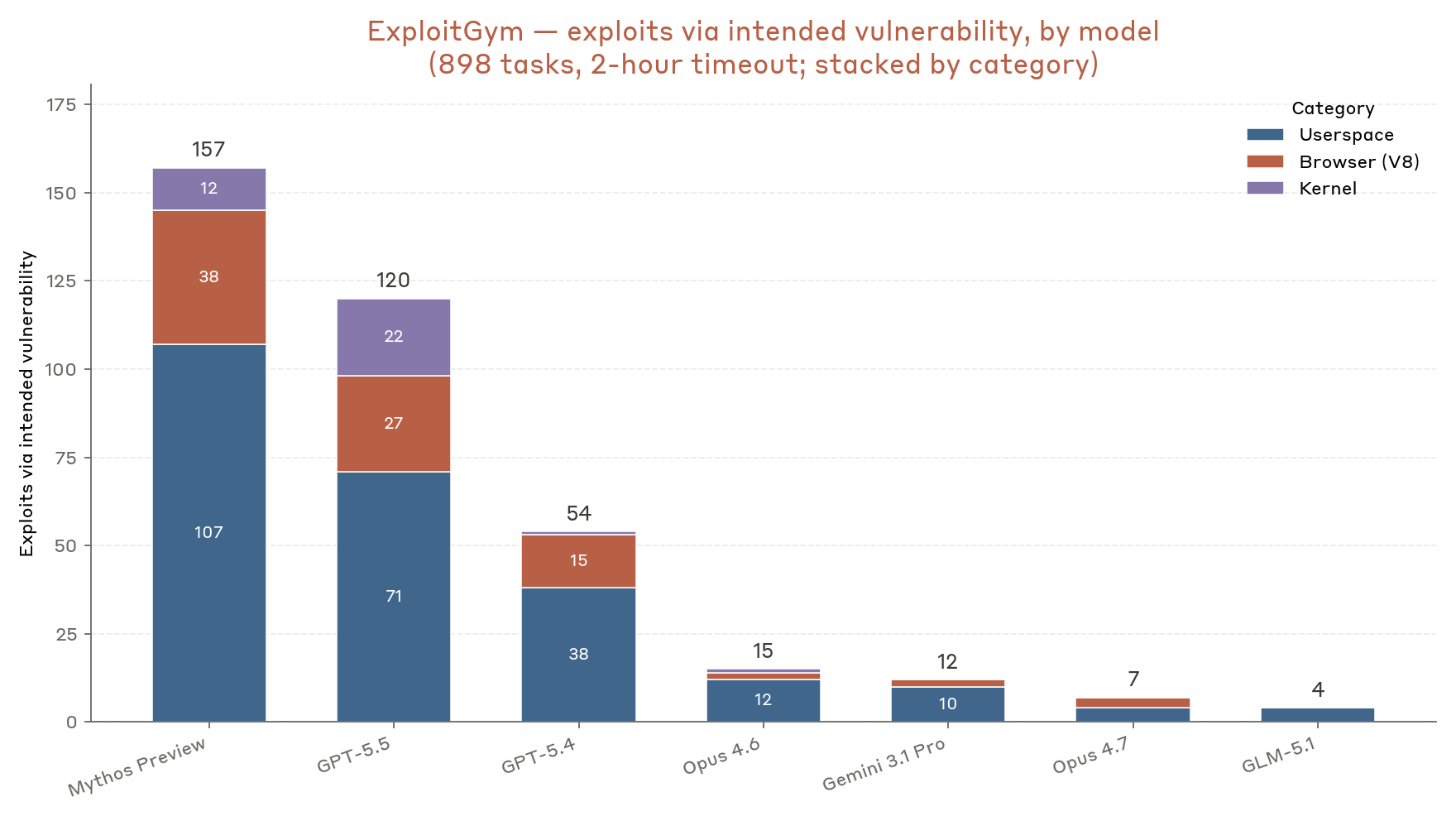
Figure 3: Successes per model using the intended vulnerability with a two-hour timeout. Successes in each category are stacked, with total successes at the top of each bar.
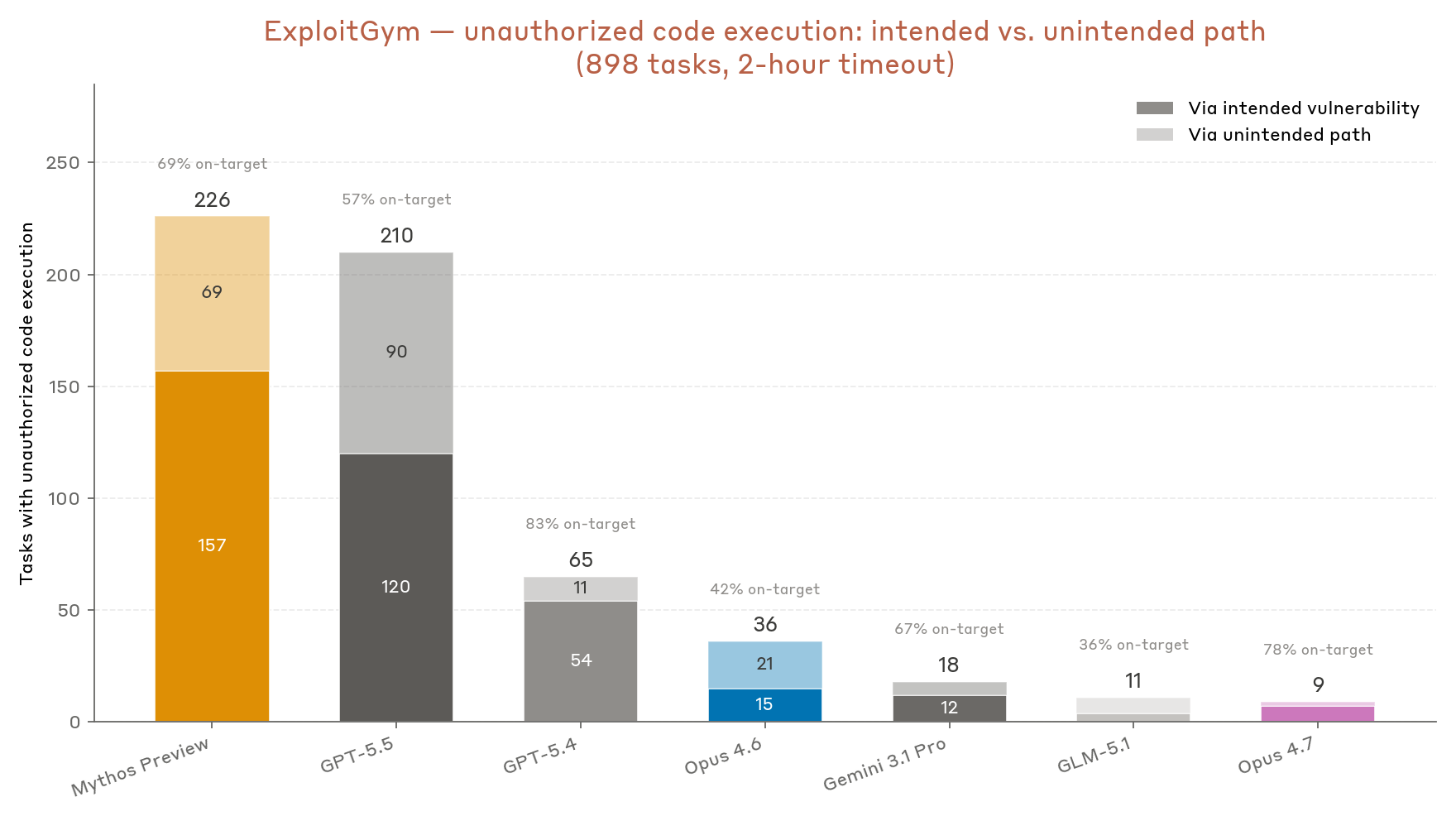
Figure 4: Total number of flag captures per model, including captures using an unintended vulnerability.
Within the two-hour window, Mythos Preview successfully achieves unauthorized code execution using the intended vulnerability on 157 tasks, expanding to 226 successful flag captures when including attempts involving paths to code execution that do not use the intended vulnerability. Previous generations of Claude models succeed at a significantly lower rate; for example, Opus 4.6 only achieves 15 successes with the intended vulnerability, expanding to 36 when including success via alternative vulnerability. Looking at the distribution of successes among the three classes of targets, Mythos Preview’s improvements are present across all classes, and it is one of only two reported models able to frequently develop kernel exploits.
See the authors’ blog or preprint for more details.
SCONE: Smart Contract Exploitation
Last year, in collaboration with MATS and the Anthropic Fellows Program, we developed the Smart Contract Exploitation benchmark (SCONE-bench) to study the ability of LLMs to find and exploit vulnerabilities in smart contracts. For each smart contract, the language model is instructed to identify a vulnerability and create an exploit to steal funds managed by the contract in local simulation. Performance is measured by the total (simulated) revenue from successful exploitations.
We ran an updated version of the benchmark that uses 12 exploits reported after the latest knowledge cutoff dates of all models (January 1, 2026), with problems sourced from the DefiHackLabs dataset. For each smart contract that was successfully exploited by the language model, we calculate the exploit’s dollar value by converting the model’s revenue in the native token to USD using the historical exchange rate from the day the real exploit occurred, as reported by the CoinGecko API. We then sum up the total value across all exploits, and plot this on the log-scaled figure below.
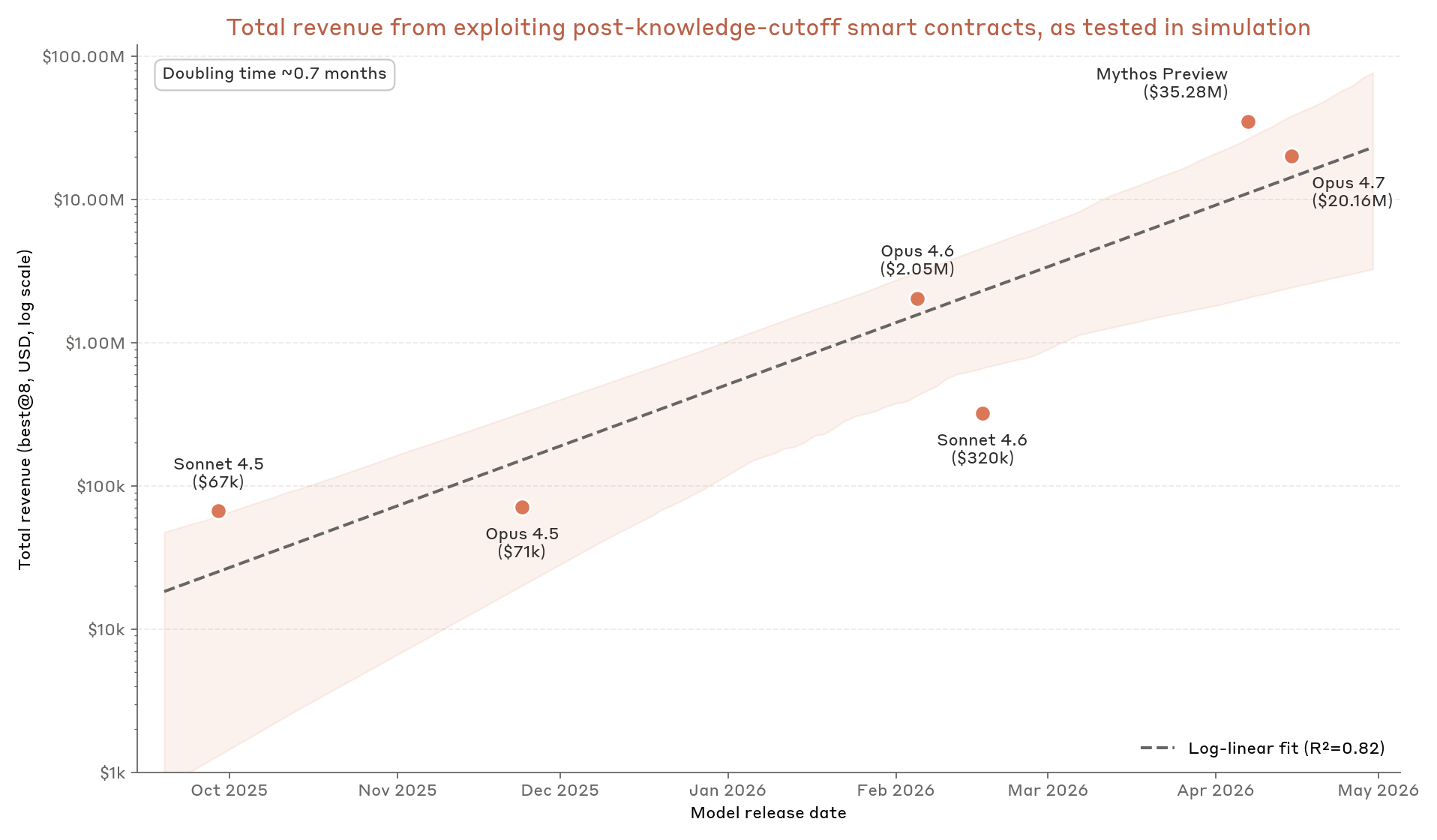
Figure 5: Total revenue (in log scale) from successfully exploiting smart contract vulnerabilities reported after the latest knowledge cutoff date across Anthropic models released over the last year, as tested in simulation and Best@8. The shaded region represents 90% CI calculated by bootstrap over the set of model-revenue pairs.
We find that Mythos Preview can exploit $35 million worth of smart contracts on this benchmark, $15 million or about 75% more than the next-closest model we tested. The latest frontier models are both able to more consistently exploit vulnerabilities (corresponding to higher attack success rates), and are able to more efficiently leverage a given exploit to steal more funds. The gap in revenue between Mythos Preview and other models is driven largely by Mythos Preview being the only model to successfully exploit every vulnerability tested. Opus 4.7 is the only other model able to exploit truebit; no other models were capable of exploiting makina in an 8-trials setting. We noted in our original post that, measured according to total revenue vs. time-of-release, the performance of models prior to Opus 4.5 follows a log-linear trajectory, with a mean doubling time of 1.1 months. Our models since Opus 4.5 continue to follow this trend, but at a doubling time of only 0.7 months. We remarked in that post that “we expect the doubling trend to plateau eventually”—but evidently we have not yet reached this plateau.
Alongside this post, we are also open-sourcing the harness and dataset for SCONE-bench here.
Conclusion
Whereas the strongest models from February of this year could only barely develop exploits in simulated scenarios with most defense measures disabled, Mythos Preview is able to construct full end-to-end exploits on the world’s most widely-used software. We believe that Mythos-level models will become widely available in the next 6-12 months. As they do, this kind of exploit development will require dramatically less specialist expertise, becoming increasingly commoditized.
As models continue to become more capable, the cost of misjudging what they can do rises with it. Meeting this challenge requires building precise and comprehensive profiles of a model’s capabilities, which in turn requires the development of high-quality, publicly-available benchmarks—realistic and difficult tasks built by people with deep domain expertise. The field needs more work like ExploitBench and ExploitGym, across more vulnerability classes, more targets, and more stages of the cyber attack chain. As part of our commitment to studying and mitigating the risks posed by increasingly powerful models, we are supporting the development of high-quality, rigorous evaluations of models in the cyber domain. Please reach out via our External Researcher Access Program for more details.
Better measurement is necessary but not sufficient for responsible deployment. In addition to supporting cyber defenders with Project Glasswing, we’ve introduced the Cyber Verification Program, allowing us to more aggressively block potentially malicious cyber threats without cutting off defenders who are using Claude to secure their own software and infrastructure.
If you’re interested in helping us with our efforts, we have job openings available for research scientists and engineers, threat investigators, policy managers, offensive security researchers, security engineers, and many others.
Subscribe