用 BioMysteryBench 评估 Claude 的生物信息学研究能力
来源: Anthropic Research | 作者: Brianna (Anthropic Discovery Team) | 日期: 2026-04-30 原文链接: https://www.anthropic.com/research/Evaluating-Claude-For-Bioinformatics-With-BioMysteryBench
一句话总结
Anthropic 发布了 BioMysteryBench——一个包含 99 个基于真实数据的生物信息学基准测试,结果显示最新一代 Claude 在人类可解问题上与专家持平,在人类困难问题上以 30% 的解题率超越五人专家团队,核心优势在于海量知识与多方法交叉验证。
速览
- 为什么科学基准测试难以标准化——生物学研究路径多元、决策主观、数据噪声大,且许多问题人类自身尚未解决
- BioMysteryBench 的设计哲学——99 个问题基于数据的可控客观属性(而非科学家结论),答案经实验验证,允许”超人类”问题生成
- 方法无关评测——模型可自由选择分析工具和策略,仅按最终答案评分,不受单一研究者主观选择约束
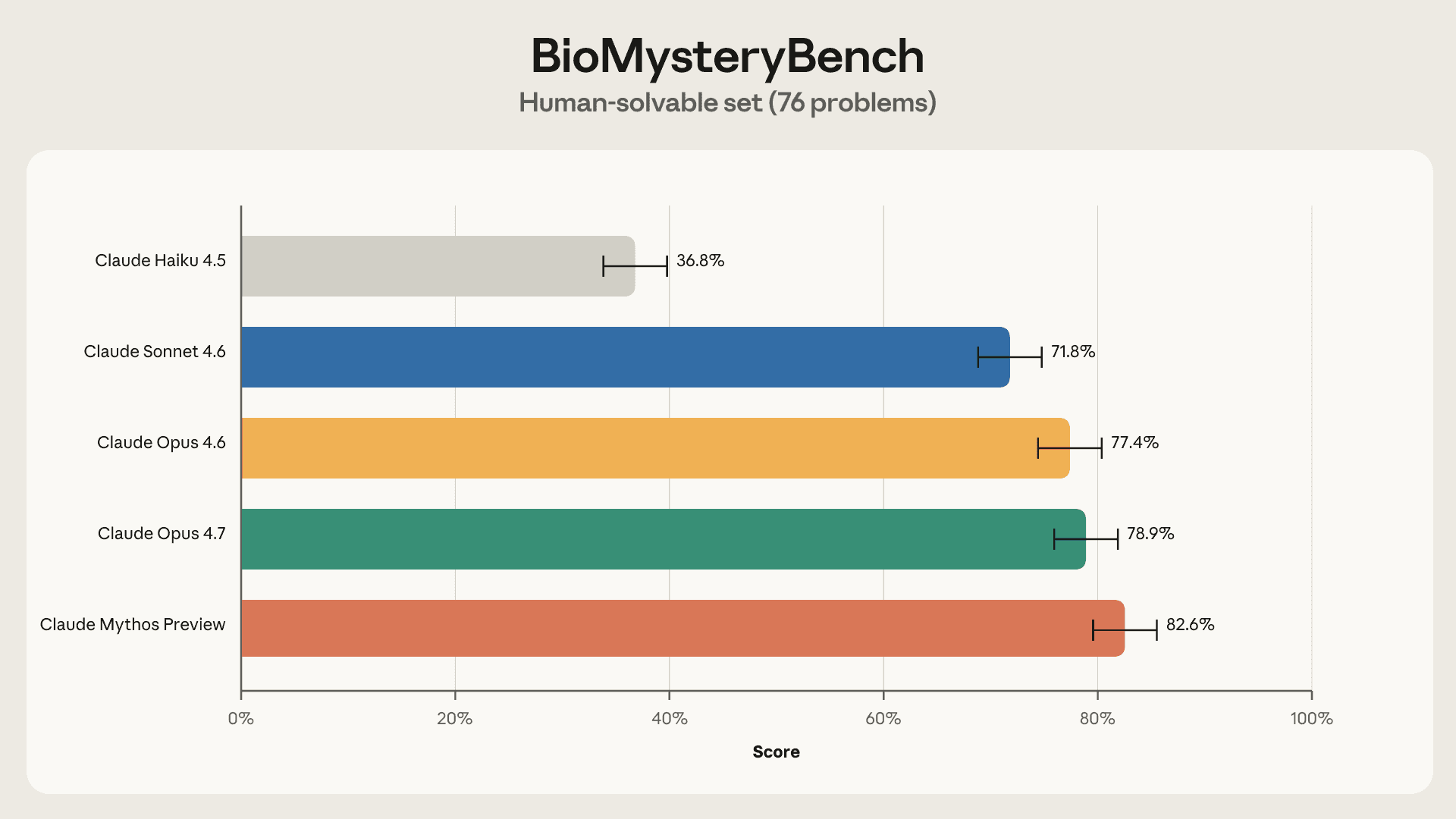
- 人类可解问题表现——Claude 各代在 76 个人类可解任务上稳步提升,最新模型表现与人类专家持平
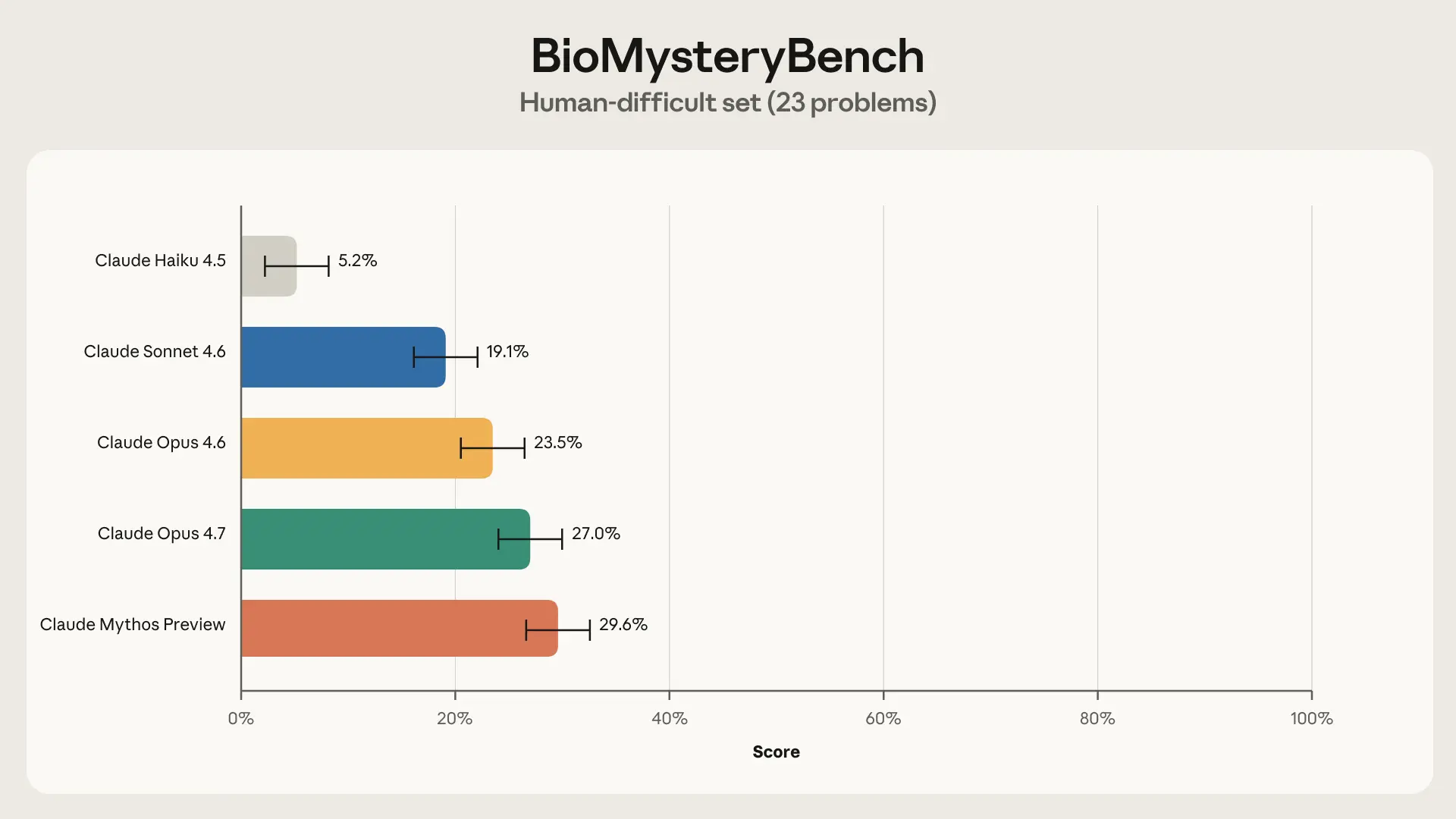
- 人类困难问题突破——Claude Mythos Preview 在 23 个人类专家团队无法解决的问题上达到 30% 解题率
- “全知全能”策略——Claude 利用预训练中数十万篇论文的知识,直接完成人类需要 meta 分析才能处理的任务
- “知道自己不知道”策略——当不确定时,Claude 叠加多种方法并选择多条证据线趋同的答案
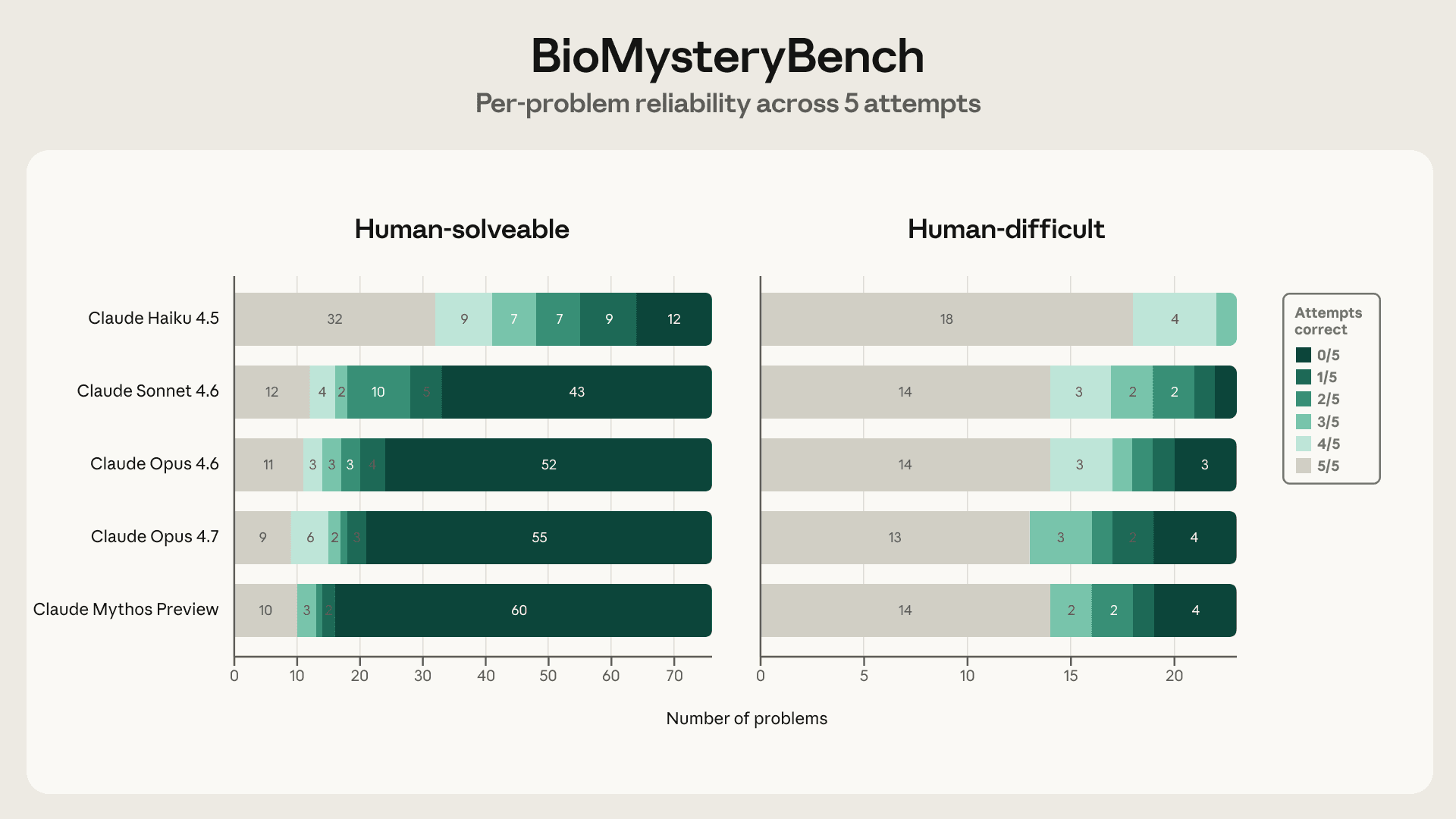
- 可靠性差距比准确率差距更关键——人类可解问题上模型呈双峰分布(全对或全错),困难问题上近半数胜利是不可重复的”幸运路径”
- Genentech/Roche 独立验证——CompBioBench 的 100 个计算生物学任务中 Claude Opus 4.6 达到 81%,与 BioMysteryBench 结论互相印证
核心内容
科学基准测试的三重困境
生物学研究的评测面临三个根本性挑战:
路径多元性——同一个研究问题(如”为什么部分糖尿病患者对二甲双胍无反应”)可以通过 GWAS 研究遗传变异,也可以通过肠道微生物组测序来回答,两条路径都合理,选择取决于研究者的专业背景和可用资源。
决策主观性——即使在同一研究方向内,个体决策也高度主观。生物数据集噪声大,微小的研究设计差异就能导致截然不同的结论。文章以二甲双胍反应预测因子的十年研究为例:2011 年论文报告一个预测变异并在两个队列中复制,2012 年另一项研究在前驱糖尿病患者中完全未能复制,同年的 meta 分析则认定效应真实但更温和。
人类知识边界——最有价值的研究任务恰恰是人类尚未解决的问题。二甲双胍开发三十年后,其主要靶点仍不确定。
现有基准测试各有取舍:BixBench 按结论评分但受限于单一科学家的主观选择;SciGym 用模拟器保证真实答案但与真实数据的关联性存疑;MMLU-Pro、GPQA 等仍停留在知识问答层面,未涉及完整研究工作流。
BioMysteryBench 的设计:方法无关 + 客观真实标准
BioMysteryBench 由领域专家编写 99 个问题,覆盖 WGS、scRNA-seq、甲基化、ChIP-seq、宏基因组学、Hi-C、蛋白质组学和代谢组学。
核心设计原则:
- 问题来源于数据的可控属性:如”这个晶体结构属于哪种生物体""根据 RNA-seq 数据,患者感染了哪种病毒”——答案经实验(如 PCR)或元数据验证
- 方法无关:Claude 被放入配有标准生物信息学工具的容器,可通过 pip/conda 安装额外工具,可访问 NCBI、Ensembl 等数据库,自由选择分析策略
- 仅按最终答案评分:不评判分析路径,消除单一研究者主观选择的偏差
- 允许超人类问题:每位问题作者提交验证 notebook 证明信号存在于数据中,但不要求问题必须是人类可解的(验证答案比推导答案容易得多)
示例问题包括:识别 scRNA-seq 数据来源器官、从 RNA-seq 判断敲除基因、从 WGS 推断亲子关系、区分 ChIP 和 input 对照的 bigWig 文件、从 H3K27ac ChIP-seq peaks 识别细胞类型。
Claude 的表现:人类可解 vs 人类困难
人类可解问题(76 个):由至少一名人类专家(最多五人团队)正确回答。Claude 各代准确率稳步提升,最新模型与人类专家持平。
人类困难问题(23 个):五人专家团队均未能正确回答。经质量控制移除 4 个有缺陷的问题后保留 23 个。Claude Sonnet 4.6 及以上模型能解决相当比例,Claude Mythos Preview 达到 30% 解题率。
Claude 的两大核心策略
“全知全能”(Know-it-all):Claude 的预训练知识库包含数十万篇论文中的结构生物学、分子图谱和 meta 分析信息。需要人类专家进行 meta 分析或拼接多个数据库才能完成的任务,Claude 通过将内部知识与实时分析结合直接解决。但先验知识偶尔也成为软肋——在人类可解集中出现过因先验知识干扰而失败的案例。
“知道自己不知道”(Knowing when you don’t know):当 Opus 4.6 对答案不自信时,它尝试多种不同方法解决同一问题,选择多种方法趋同的答案。这种多方法交叉验证的策略值得人类科学家学习。
Claude 还展现出一种类似”直觉”的能力——人类专家使用算法或数据库来识别数据集属性,而 Claude 能直觉地识别某些模式或序列,类似于科学家注意到基因上游序列中反复出现”TATA”序列从而发现第一个真核生物启动子。
可靠性差距:比准确率更深层的故事
Claude Mythos Preview 的自我分析揭示了准确率数字背后更有趣的维度:
- 人类可解问题呈双峰分布:Opus 4.6 能解决的问题中 86% 至少解决了 5 次中的 4 次——要么有可靠方法,要么完全不会
- 人类困难问题分布平坦化:可靠解题比例从 86% 降至 44%,脆弱胜利(仅解决 1-2/5 次)从 9% 跃升至 44%
- Sonnet 4.6 的转变更为剧烈:75% 可靠 → 22%,9% 脆弱 → 56%
- 本质区别:可解问题上模型在”检索”可靠知道的东西,困难问题上近半数胜利是偶然碰到的推理路径
这意味着 77.4% → 23.5% 的标题准确率下降实际上低估了真实情况——可靠性差距才是能力前沿真正位置的更准确指标。
与外部研究的趋同验证
Genentech 和 Roche 同期发布的 CompBioBench 包含 100 个计算生物学任务,基于合成/增强数据,要求多步推理、工具使用和真实世界资源交互。Claude Opus 4.6 在该基准测试中总体达 81%,最难问题达 69%——与 BioMysteryBench 的结论互相印证,独立验证了前沿模型已成为生物信息学研究的有效合作者。
名言金句
- “Competition aside, benchmarks help us tackle an important question: whether models are capable and reliable enough to support, or even produce, professional-level work.”
- “If there were only one right way to answer a research question, PhD students would earn their degrees in a matter of months.”
- “Intuition like this has been difficult to build into traditional biology machine learning models, but LLMs might be able to turn up patterns like this at unprecedented scale.”
- “The accuracy gap is real, but the reliability gap underneath it is the more interesting story about where the capability frontier actually sits.”
- “Models are no longer merely keeping up with trained scientists on bioinformatics problems; on some tasks, they’re ahead.”
可行建议
- 生物信息学研究者:可以将 Claude 作为分析助手,尤其在需要跨数据库 meta 分析或多方法交叉验证的场景中
- AI 评测设计者:BioMysteryBench 的”基于数据可控属性设问 + 方法无关评分”范式值得借鉴,适用于其他科学领域的基准测试设计
- 模型使用者:注意当前模型在困难问题上的”脆弱胜利”现象——单次正确不代表方法可靠,重要结论应多次验证
- 科学 AI 社区:可通过 scienceblog@anthropic.com 向 Anthropic 提交基准测试和创新用例