Coding 没壁垒之后,什么才值得做
一个正在发生的矛盾
AI 用了,效率高了,钱没多赚。该上的工具都上了,该试的场景都试了,但年底一算账,利润没动。
黑客松上更明显。每次比赛几百个项目,idea 满天飞,demo 看着都挺酷。但做完就是没人用——连那些拿到投资的,也说不清到底解决了什么真问题。
这不是个别现象。SimpleClosure《2025 年创业公司关停报告》显示,2025 年 AI 公司占所有关停的约 16%,其中应用层和 wrapper 类产品承受了最剧烈的调整——这类产品建立在商品化的模型之上,缺乏足够深的防御性壁垒¹。单是 Builder.ai 一家就烧了 4.45 亿美元,估值曾冲到 15 亿美元,最后破产清算。2026 年 2 月,Google VP Darren Mowry 公开说:LLM wrapper 这种模式的”发动机警告灯已经亮了”²。
为什么?大部分人觉得是分发问题——推不出去。但问题可能根本不在分发,而是这些产品做的事,压根就没减少什么摩擦。
读完这篇你能带走什么
- 判断 AI 产品价值的框架:摩擦消除 × 可防御性 × 基建复利
- “长任务”和”高信息密度”——为什么同样用了 AI,价值差出几个量级
- 壁垒不是技术,是”最后一公里”的上下文和方法论
- 人在 AI 时代真正不可替代的两件事:Context 管理和品味判断
- 怎么评估你的壁垒能撑多久
🔍 大部分 AI 产品,其实没减少多少摩擦
互联网当年”线下转线上”,摩擦消除是巨大的。原来转账要跑银行排队半小时,现在手机上点两下。原来买东西要去商场挑半天,现在搜一下第二天到家。那种摩擦消除是不可逆的——用过就回不去了。
但现在很多 AI 产品处理的是另一类事:问个问题、改个措辞、生成一段文案。这些任务本身就很短,你算一下时间成本就知道了——原本鼠标点几下两秒钟搞定的事,换成 AI 要你先打字描述需求、再等它输出 10 秒钟、然后还要读一遍检查对不对。单看每一次交互,AI 反而增加了摩擦,而不是减少。
这个学习成本比大部分人想的要高得多。学会用一个工具只是开始——你还得学怎么写 prompt、学怎么判断 AI 什么时候靠谱什么时候在瞎编、学怎么把 AI 嵌进自己的工作流程。这不是看个教程就搞定的事,是一个持续的、需要不断练习的过程。如果你的应用场景本身就很浅——就是问个问题、改改措辞——那这些学习投入的价值根本体现不出来。花了大量时间学 AI,结果只是偶尔用它改改错别字,怎么算都不划算。
还有一类产品,想法不错,但上下游生态链不成熟,实际用起来摩擦没真正减少。Humane 的 AI Pin 是个极端例子——融了 2.3 亿美元,把大模型塞进一个可穿戴设备,想替代手机。结果上市后被 MKBHD 等主流科技评测圈评为近年最差产品之一³,2025 年以 1.16 亿美元卖给了 HP。它不是没有 AI,而是这个形态反而让交互变得更麻烦了。
摩擦消除不是”用了 AI”就自动成立的。 它取决于你解决的任务本身够不够深——只有足够深的任务,才值得你投入时间去学好 AI、用好 AI。
📐 什么才是有价值的 AI 产品
拆开来看,有价值的 AI 产品大致有这么几种方向。
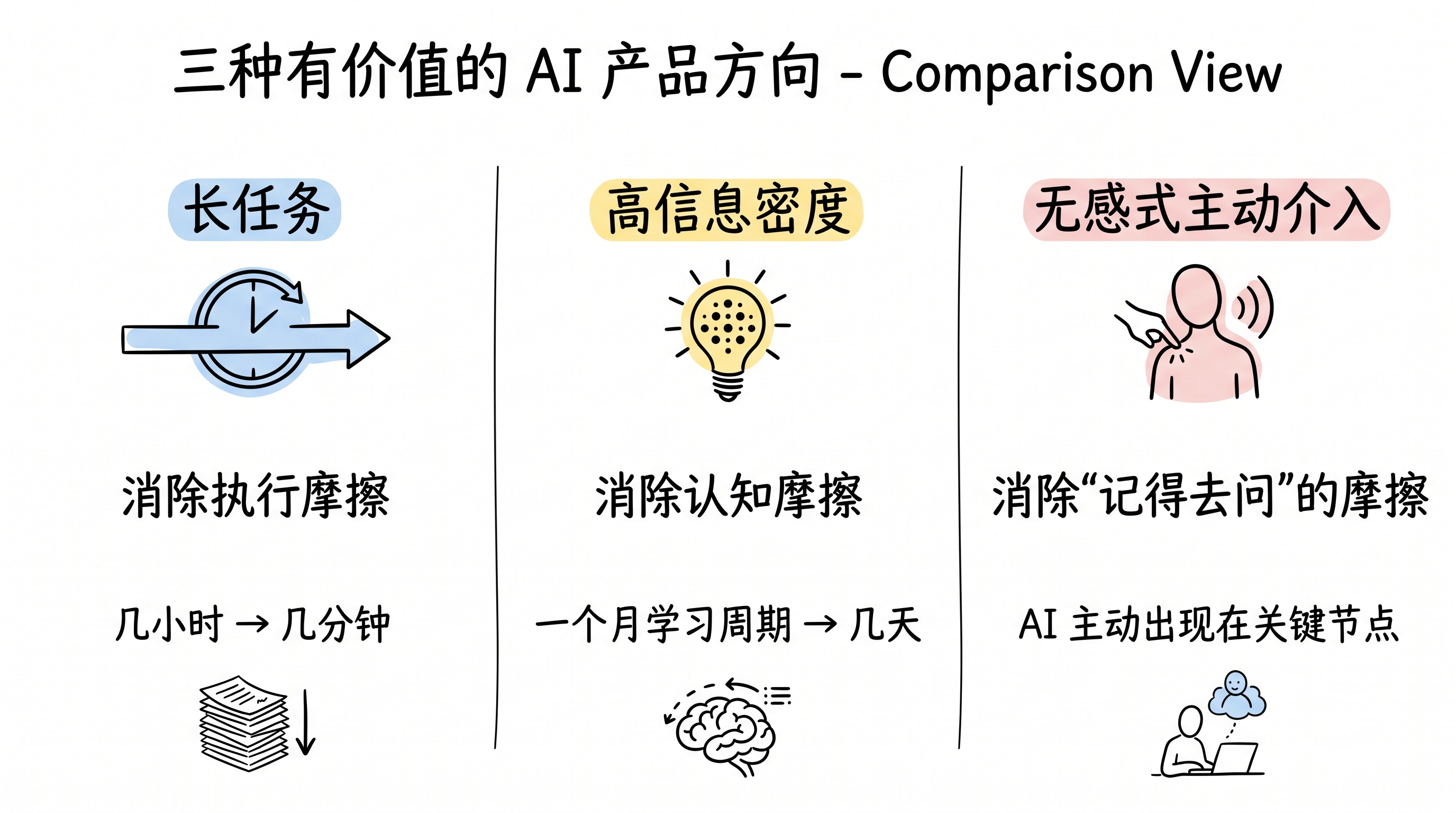
第一种:做”长任务”
把一个原来需要几小时甚至几天的复杂流程,基本端到端地完成。即便流程两头还需要人介入,只要人工部分的时间占比足够小,这种摩擦消除就是量级性的。
Tome 是一个早期的典型。2022 年底,大模型能力刚起来的时候,Tome 让你输入一段描述就能生成一套完整的演示文稿——不是帮你改一页 PPT,而是从零到一完成整个演示。这比”帮你润色一段文案”要深得多,是一个真正的长任务。用户用完确实觉得”回不去了”,Tome 很快积累了 2000 万用户,融了 8100 万美元⁴。同赛道的 Gamma 也是同一个逻辑——硅谷团队创办,2025 年拿到 a16z 领投的 6800 万美元,估值 21 亿,年营收突破 1 亿美元⁵。AI PPT 这个方向能拿到这么多钱,说明”端到端完成一个长任务”确实是被市场验证过的方向。
但 Tome 的故事后面还有转折,我们等一下再说。先看一个更扎实的长任务案例。
2026 年 Anthropic Opus 4.6 黑客松的前三名都不是开发者——是一位加州律师、一位布鲁塞尔的心脏科医生、一位乌干达的道路工程师。13000 人报名、500 人参赛⁶。
律师 Mike Brown 夺冠的项目叫 CrossBeam,解决的是加州 ADU(附属住宅)的许可证审批——这类申请首次提交驳回率超过 90%,平均延迟 6 个月,额外成本 3 万美元。Brown 用六天时间做了一个端到端的审批助手,从材料整理到提交策略全流程走通。
为什么非开发者能赢?因为许可证审批是典型的长任务——不是回答一个问题,而是走完一整个流程。更关键的是,这个流程需要加州建筑法规、各市具体条例、历史驳回模式这些上下文,大模型裸跑根本做不好。Brown 比任何开发者都更懂这些细节——他的壁垒不是”会用 Claude”,而是脑子里装着加州建筑法规和审批员偏好的执行细节。
同样的逻辑在法律科技公司 Harvey AI 身上得到了规模化验证。Harvey 做的是法律文书审查——一个需要多步骤、高专业门槛的长任务。2025 年 12 月完成 a16z 领投的 1.6 亿美元 Series F,估值 80 亿美元,AmLaw 100 前 50 家律所都已是客户⁷。
第二种:提供高信息密度
不是帮你产出什么东西,而是在每轮交互里给你高质量的认知增量。这种任务本质上也是在减少摩擦——减少的是学习和筛选知识的时间摩擦。
想想看,在没有 AI 的情况下,你要深入了解一个陌生领域,得花大量时间去搜索、阅读、筛选、对比、验证。一个复杂话题可能要花一个月才能真正搞明白。但如果有一个好的 AI 工具,它能把这个过程切成一节一节的交互——每一节都帮你压缩掉 80% 的搜索和筛选时间。一个月的学习周期可能几天就走完了。
但关键在于,大模型本身的信息量虽然极其丰富,什么都知道一点,“什么都知道”不等于”能给你有用的”。信息要产生价值,必须有方法论在背后引导——在合适的时机、用合适的方式,把合适的内容调出来。
举个例子:你做一个行业调研工具,大模型知道所有行业的基础知识。但如果没有一套方法论告诉它该从哪些维度切入、该交叉验证哪些信源、该在什么节点做收敛,它给你的只是一堆”看起来什么都有但拼不成判断”的散装信息。信息价值的本质是信息筛选的能力。
第三种:无感式的主动介入
还有一种产品形态可能是最难做、但一旦做成也最受欢迎的:AI 不等你来问,而是在你做事的每个关键节点主动出现,给你需要的信息,或者直接帮你把事情做了。整个过程你几乎无感,甚至是完全被动的。
这种产品看起来有点像长任务,但其实不是——它是一系列离散的小任务,分布在你工作流程的各个节点上。每个单独的小任务可能很短,但它们精准地出现在你需要的时刻,累积起来就是巨大的摩擦消除。
为什么说它最难?因为要做到”在你需要的时候出现”,产品必须拿到极其精准的上下文——知道你在做什么、做到哪一步了、下一步可能需要什么。还需要精准的提示词设计和足够强的模型能力,才能做到既不打扰你又不遗漏你真正需要的东西。这对 Context 的管理要求是最高的。
三种有价值的方向,本质都是摩擦消除
- 长任务:把几小时/几天的复杂流程端到端压缩到几分钟。消除的是执行摩擦。
- 高信息密度的短交互:把一个月的学习/调研周期压缩到几天。消除的是获取认知过程中的摩擦。
- 无感式主动介入:在你工作的每个关键节点精准出现,消除的是”你还得记得去问 AI”这层摩擦。最难做,但做成后用户最离不开。
🛡️ 光有价值还不够——壁垒在哪
减少摩擦是必要条件,但不是充分条件。
还记得前面说的 Tome 和 Gamma 吗?同一个赛道,都做 AI 演示文稿,都是长任务。但结局完全不同。
Tome 的 2000 万用户几乎不付钱,年营收只有 350 万美元⁴。2024 年 10 月大规模裁员,2025 年 4 月正式关闭 PPT 产品。为什么?因为”输入提示词,出一份 PPT”这件事,大模型裸跑就能做。用户试一次觉得新鲜,第二次就回 ChatGPT 了。Tome 解决的是长任务,摩擦确实减少了——但它没有壁垒。
而 Gamma 年营收 1.02 亿美元,是 Tome 的近 30 倍。Gamma 比 Tome 多做了一步——把 AI 嵌进了设计工作流,布局引擎、品牌一致性、数据可视化,不是简单的”自动生成”,而是在设计过程中持续提供辅助。靠这个,Gamma 在 2025 年活得很好。
但到了 2026 年,这层壁垒也在松动。Claude 已经能直接生成演示文稿,有人用一个 Claude Skill 生成的幻灯片,比大多数专业 PPT 工具做出来的还好看⁸。Gamma 在 Trustpilot 上只有 1.7 分,74% 是 1 星差评⁹,用户骂得最多的就是导出 PPT 时排版崩坏、字体丢失、布局错位——在真正需要专业交付的场景里,它反而不行。Gamma 也在主动横向扩张品类,2026 年 3 月推了 Gamma Imagine 图片生成功能,从 PPT 工具延伸到 Canva 和 Adobe 的视觉内容地盘¹⁰——因为光靠 PPT 这一个品类,壁垒已经不够了。
这说明一件事:方法论壁垒也分深浅。 “怎么做好看的 PPT”是方法论,但这个方法论大模型正在学会。
Jasper AI 是另一个教训。2022 年以 15 亿美元估值融了 1.25 亿美元 Series A。核心功能:帮营销人员写文案。ChatGPT 发布后,用户发现花 20 美元订阅 ChatGPT 就能做一样的事。增长放缓、内部估值下调,创始 CEO 和 CTO 于 2023 年 9 月双双卸任¹¹。
规律很清楚:如果你做的事大模型裸跑就能做到,或者别人一抄就有,那摩擦再少也没壁垒。 即使你沉淀了方法论,如果这个方法论的门槛不够高——像”怎么排版好看”这种——模型迟早会学会,壁垒迟早会被追平。
那什么样的壁垒才够深?真正的壁垒是上下文——你能给 AI 提供什么别人提供不了的信息。同一个模型,喂不同的上下文,输出质量天差地别。
上下文里最核心的是两部分:数据和方法论。
数据是”原材料”。 没有数据,再聪明的模型也做不了任何事——就像再强的分析师,不给他业务数据也分析不出什么。大模型通过训练已经吃透了互联网上的公开数据,真正构成壁垒的是那些模型训练时根本接触不到、只存在于你这里的原始数据:一家医院多年积累的病历、一家工厂设备的运行日志、一家律所案件的执行档案和往来沟通、一家电商平台的真实用户行为数据。这些数据没有公开来源,模型无论怎么训练都拿不到。
就算是看起来公开的领域,也有”最后一公里”的数据壁垒。建筑法规是公开的,法律条文是公开的——但具体到每个市怎么执行、每个审批员怎么判、每个客户的历史偏好是什么,这些执行层面的原始记录只存在于实际做过事的人手里。Harvey AI 的壁垒也是同样的逻辑——法律条文是公开的,但各家律所内部积累的案件档案、客户沟通记录、合规修订历史,这些都是模型够不到的原始数据。
方法论是”怎么用这些数据”。 同样的数据摆在那里,不同的人能产生不同的价值——这中间的差别就是方法论。写在提示词的示例里,写在思维链的推理步骤里,告诉模型”遇到这类问题应该按这个路径去想,应该从数据里提取什么样的信号”。模型本身什么都知道一点,但它不太确定该用哪条路径——你给的方法论就是那条路径。当你教给模型的东西是别人教不了的,那就是你的方法论壁垒。
数据是底层的原材料,方法论是上层的加工规则。两者都需要——光有数据没方法论,数据就是死的;光有方法论没数据,方法论就是空壳。

至于怎么把数据和方法论灌进模型——微调、RAG、上下文注入——这些工具和框架现在已经非常成熟了,云平台微调成本很低,GitHub 上的开源框架一搜一大堆,技术手段不是壁垒。
真正的壁垒是上下文和场景的匹配。 有独特上下文的人会自然找到适合的应用场景,深耕特定场景的人也会自然知道该去积累什么样的上下文。这两者是互相牵引的——你越深入一个”最后一公里”的场景,就越清楚需要什么数据、需要沉淀什么方法论;积累得越多,就越能发现新的场景机会。
而且这个壁垒有飞轮效应:产品用得越多,积累的”最后一公里”数据越多,产品越好用,用户越不想走。Glean 做企业搜索就是这个逻辑——接入了公司内部几十个系统的数据之后,迁移成本极高,估值 72 亿美元¹²。
但也要诚实说:这个壁垒不是绝对的。模型推理能力在变强,“最后一公里”的距离本身也在缩短。所以真正持久的壁垒可能不是某一时刻的数据优势,而是持续积累和结构化”最后一公里”数据的速度——你比对手更快地把新数据变成产品能力。这一点,又绕回了下面要说的基建。
⚡ 基建决定了你能跑多快
前面讲的是”做什么有价值”。但还有一个维度经常被忽略:做同样的事,谁的基建更完善,谁就能迭代得更快。
这里说的基建不只是工具链。它包括:怎么自动采集这个领域的上下文、怎么把上下文处理成 AI 可用的结构、怎么把处理好的上下文喂给预编排好的工作流。整条管线的完善度和精细度,决定了迭代速度。
OpenAI 自己就是一个极端例子。2025 年 8 月,他们内部一个 3 人工程团队从一个空的代码仓库开始,用 Codex 构建一个完整的软件产品。5 个月后,代码库达到百万行量级,已经有几百个内测用户在每天使用。团队后来扩到 7 人,每人每天合并 3.5 个 PR。
整个过程中没有一行代码是人手写的。 所有代码——应用逻辑、测试、CI 配置、文档、监控——全部由 AI 生成。OpenAI 自己说,这大约只用了手工编码所需的 十分之一时间¹³。
但”人不写代码”不等于”人不干活”。人的工作内容完全变了:
工程师的新角色是设计环境、明确意图、构建反馈回路。 具体来说:工程师把大目标拆成小任务,用自然语言描述给 AI;AI 生成代码并提交 PR;然后由其他 AI agent 做代码审查——早期还有人工审查,后来逐步演化成 agent 审查 agent。工程师不再逐行看代码,而是监督整个系统在不在正轨上。
让这套流程跑起来的,是背后一整套叫 Harness 的基建:
- 知识组织:一个约 100 行的 AGENTS.md 文件作为”目录”,告诉 AI 去哪找什么信息。他们试过把所有规则塞进一个大文件,结果完全失败——AI 反而被信息淹没,什么都做不好。
- 架构约束编码进 linter:代码的分层规则不是写在文档里靠 AI “自觉遵守”,而是直接编码进自动检查工具——违反规则的代码直接报错,错误信息里还内嵌了修复建议,AI 不用查文档就能自我修正。
- 自动文档维护:AI 生成代码的速度远快于文档更新速度,过时文档会误导后续 AI。他们部署了专门的 agent 自动扫描代码变更、更新对应文档。
- 完整的可观测性:AI 可以直接查日志、查指标、操作浏览器验证 UI,单次任务运行超过 6 小时(通常在人睡觉的时候跑)。
没有这套基建,同样的模型、同样的人,效率可能只有十分之一。OpenAI 团队自己总结的核心教训是:早期进展慢,不是因为 AI 不够强,而是因为环境规范不够清晰。 取得进展的唯一方式是让基建变得更好,而不是让 AI “再努力一点”。
OpenAI 的案例是 coding 层面的基建。但基建不只存在于 coding 领域——个人和公司都有自己的基建要搭。
个人基建
当一个人把自己跟 AI 协作的输入范式和输出范式都打磨好了——怎么给 AI 提供上下文、怎么让 AI 按自己想要的方式输出——这套流程本身就是个人基建。
更进一步,如果你能把生活和工作的各个部分串联起来,大部分都由 AI 帮你连接——你的阅读自动喂进调研,调研的结论自动变成写作素材,写作的反馈又反过来优化你的阅读方向——这就是你的”结界”。在这个结界里,你做的每一件事都在为下一件事积累上下文,复利效应会非常强。
公司基建
公司的基建不只是搭好 coding 的 Harness。更核心的是:怎么把公司积累的知识——客户数据、业务流程、行业经验、历史决策——构建成一个 AI 可以随时调用的知识库。让上下文的获取变得更轻、更丝滑、更无感,员工不需要手动整理一堆材料才能让 AI 干活。
做到这一步之后,很多以前需要人盯着的流程就可以由 AI 驱动自动完成。人从”执行者”变成”监督者”,就像 OpenAI 那个团队一样——人不再写代码,而是设计让 AI 正确工作的环境。
这些基建一开始肯定做不好——OpenAI 自己也说了,早期进展比预期要慢得多,不是 AI 不行,是环境没搭好。但这是一个迭代的过程,是一个一定要做的事情。前期会慢、会有很多卡点,但每解决一个卡点,基建就往前走一步,后面所有人、所有任务都受益。一旦走通,效果是爆发式的。
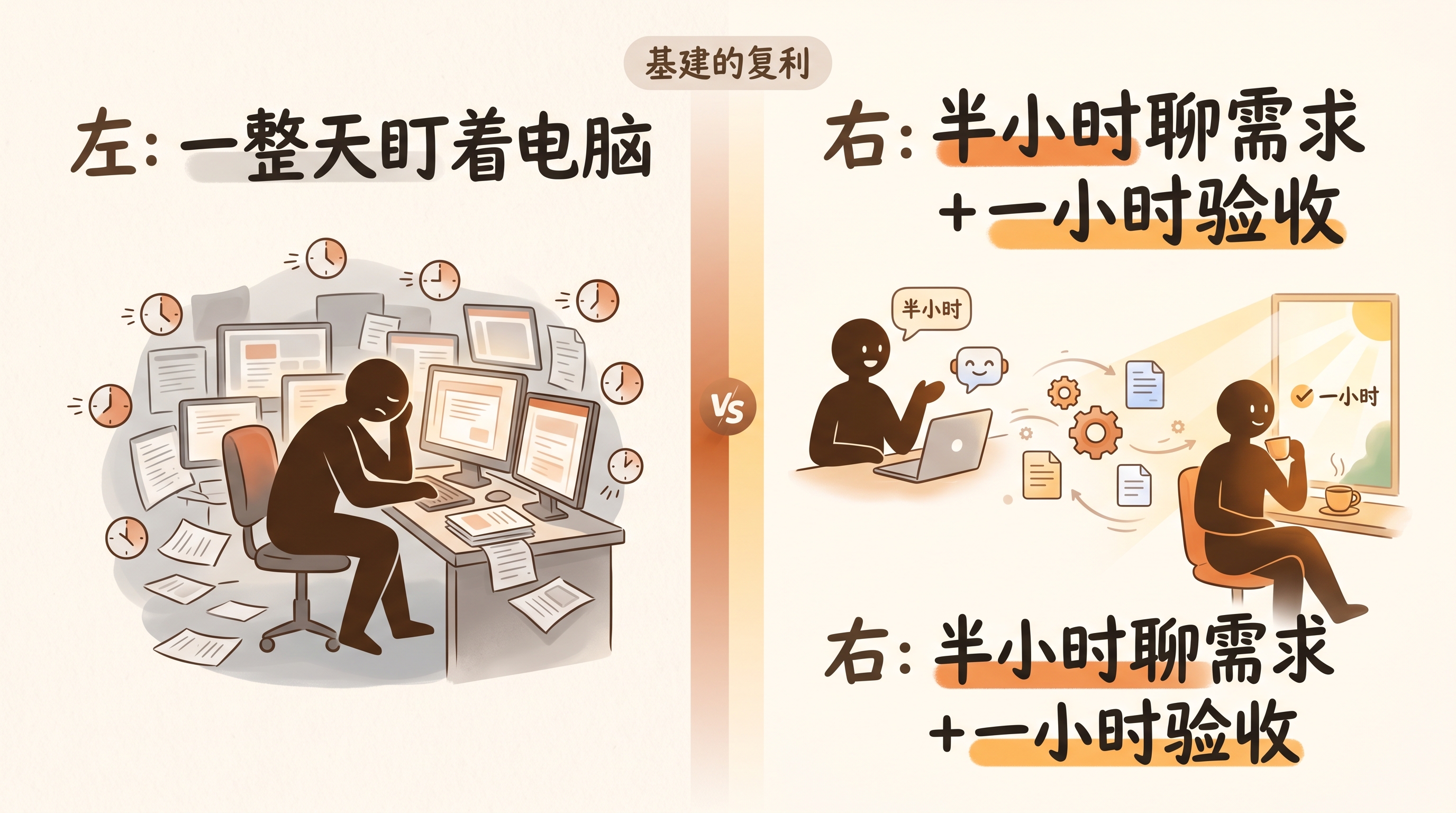
不管是个人还是公司,好的基建可以把人的注意力从”一整天坐在电脑前盯着”,减少到”开头花半小时聊需求、最后花一小时做验收”——效率差出 100 倍。10 个人用这套基建,差距就是 1000 倍。对手比你早搭好一天,就相当于跑到前面去了 100 天。这个差距不会自然缩小,只会加速扩大。
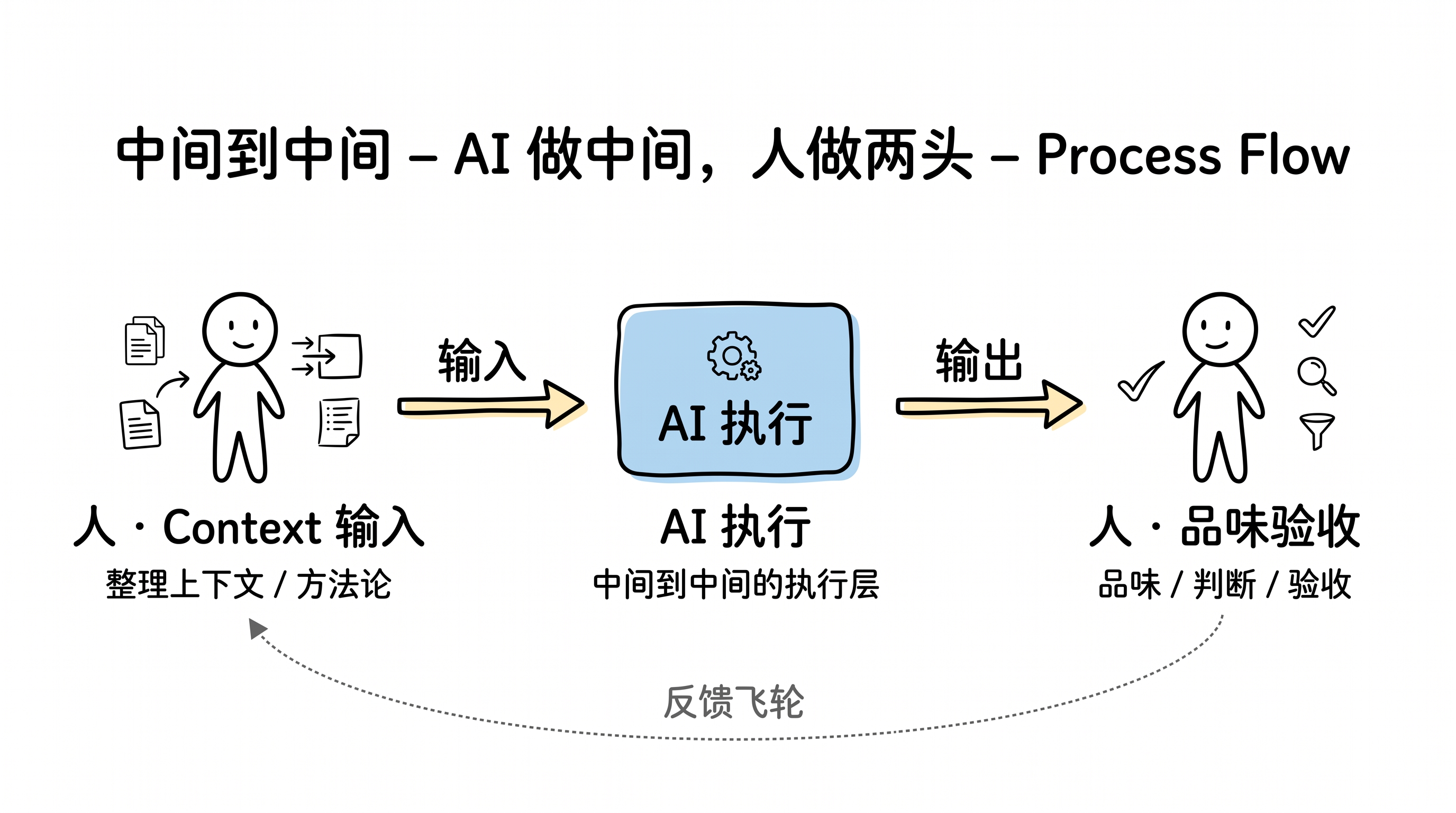
🎯 人在 AI 时代真正不可替代的是什么
模型在变强。Claude Opus 4.7 出来之后,长任务的执行能力又上了一个台阶。可以预见的趋势是:模型能执行的任务会越来越长、越来越复杂,中间的执行层会不断被 AI 吃掉。
那人还能干嘛?
其实不管 AI 怎么变强,人的工作始终在两头:前头是 Context 的整理和输入,后头是品味和判断去验收输出。 AI 做中间的执行,人做两端的把控。这就是当下正在发生的事——AI 做”中间到中间”,人做两头。
这两头不是简单的体力活。
在输入端,真正拉开差距的是上下文——前面已经讲过,数据和方法论构成了你的上下文壁垒。这里要补充一点:上下文不是一次性的投入,而是一个持续的过程。
短期看,比拼的是谁能在每次跟 AI 的对话里提供更精准的上下文。长期看,真正的差距在于谁能把这些上下文沉淀下来——变成可复用的提示词模板、思维链模板、数据管道,最终嵌进基建里。一旦嵌进去,AI 遇到对应场景就会自己调用,人不需要每次都在脑子里想”这次该用什么框架、该提供什么背景”。前端的动作可以简化到最小——丢一篇文章进去、触发一个按钮——剩下的由系统自己走完。
所以人真正不可替代的,不是”记得多少方法论”或者”知道去哪找数据”,而是能不能持续生产出别人做不到的上下文。
在输出端,大家都在用 AI 堆数量——更多代码、更多内容、更多产品。但堆数量只是入场券,真正脱颖而出的是品味。你得不断积累更高的判断标准,知道什么是好的、什么是凑合的、什么是垃圾。当所有人都在往前跑的时候,如果你除了堆数量还在堆质量,就能直接 pass 掉一大批对手。
而且这两头是互相喂养的:品味越好 → 验收标准越高 → 倒逼输入的 Context 更精准 → AI 产出质量更高 → 又进一步训练了你的品味。这本身就是一个飞轮。
回到产品层面,Context 的管理和迭代就是一个很有价值的新方向。大模型可能会一点点蚕食掉一部分 Context 整理的工作,但目前来说,上下文的收集、筛选、结构化和持续维护,仍然是需要大量人类参与的事。就像 OpenAI 团队做的那样——本质上就是在不断打磨输入端的 Context,再用好的判断去验收输出。
🔮 壁垒能撑多久
前面讲了什么有价值、什么有壁垒、基建怎么搭。但还有一个问题绕不开:你今天的壁垒,明天还在吗?
模型能力在持续增强。今天模型做不好的事,明年可能就做好了。所以任何壁垒都不是静态的,都需要持续评估。
评估的时候可以从两个角度看。
第一个是上下文对模型的效用——你提供的上下文,能不能让模型产出别人产出不了的东西?如果你的数据就是行业通用信息、你的方法论就是公开最佳实践,那模型迟早会学会,壁垒撑不了多久。只有那些模型训练数据覆盖不到的、需要在实战中长期摸索的上下文,才能长期站住。
第二个是基建的可扩展性。你的基建是不是具备高复用性?当模型能力变强的时候,你的基建能不能跟着受益,而不是被模型直接绕过?好的基建应该有这样一个特点:模型越强,基建反而越有用——因为更强的模型能在更好的基建环境里发挥出更大的效果。反过来,如果基建只是在弥补模型的短板,那模型一旦补上了这个短板,基建就没用了。
上下文的效用和基建的可扩展性——这两件事决定了你的壁垒能撑多久。 短期的壁垒靠先发优势,长期的壁垒靠持续积累那些模型真正够不到的东西。
回到最初的问题
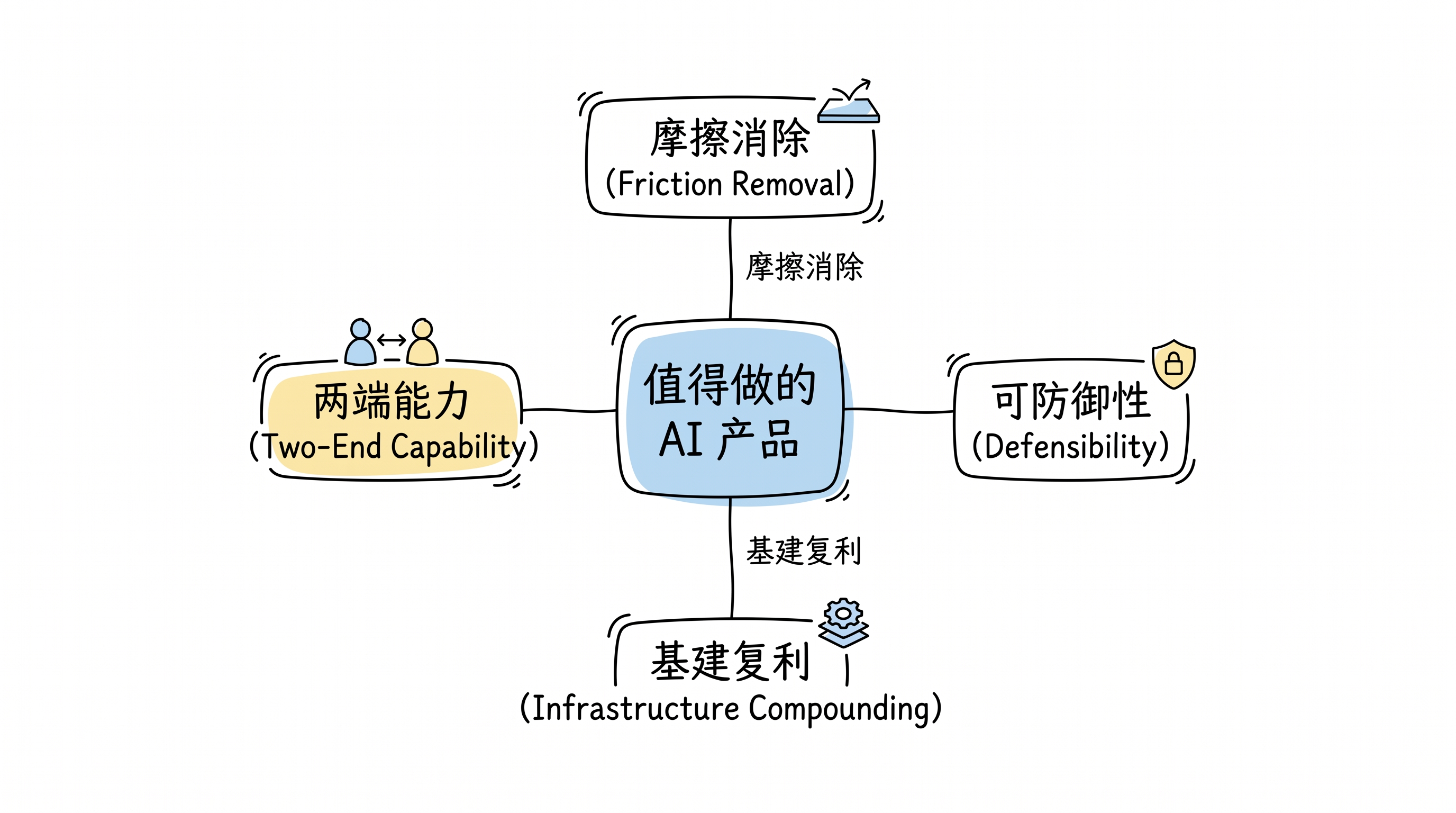
AI 让”做”变得不值钱了。Coding 能力没有壁垒了,工具框架满地都是,大模型什么都能做一点。在这个背景下,什么才值得做?
- 找到真正深的摩擦——长任务端到端地消除执行摩擦,或者通过高信息密度消除获取认知过程中的摩擦。浅摩擦不值得做。
- 占住模型够不到的位置——“最后一公里”的数据和场景,大模型训练数据覆盖不到、公开方法论替代不了的位置。
- 把基建搭起来——不管是个人的、公司的还是 coding 层面的,基建决定了迭代速度,迭代速度决定了复利。一开始肯定做不好,但这是一个必须做的事情。
- 不断提升两端的能力——Context 的整理和输入,品味和判断的验收。AI 的中间执行层会越来越强,但两端的人类能力反而会越来越值钱。
而贯穿这一切的是一个持续的追问:你今天做的事,壁垒能撑多久?上下文够不够独特,方法论够不够私有,基建够不够扩展?这些问题没有一劳永逸的答案,只有不断迭代的过程。
做得越早,积累越深,飞轮转得越快。
不过这篇聊的都是”现有的事怎么做得更好”。还有另一个更大的变化正在发生:以前的网络里节点是人,平台连接人与人。但现在 Agent 正在作为独立的智能节点加入这个网络——它不只是工具,它能自主行动、自主决策。当网络里多了这一类节点,Agent 与 Agent 之间、Agent 与人之间的连接方式都是全新的,给 Agent 赋能和给人赋能一样可以产生价值。再加上 AI 把大量事情的成本打到极低,在新的成本结构上也会长出以前根本不存在的产品。这两件事叠在一起,一定会催生出全新的生态位——但那是另一个话题了。