让 AI 一天复写 4.7 万行 Python:51 个 Phase、1657 测试全绿
一个正在发生的变化
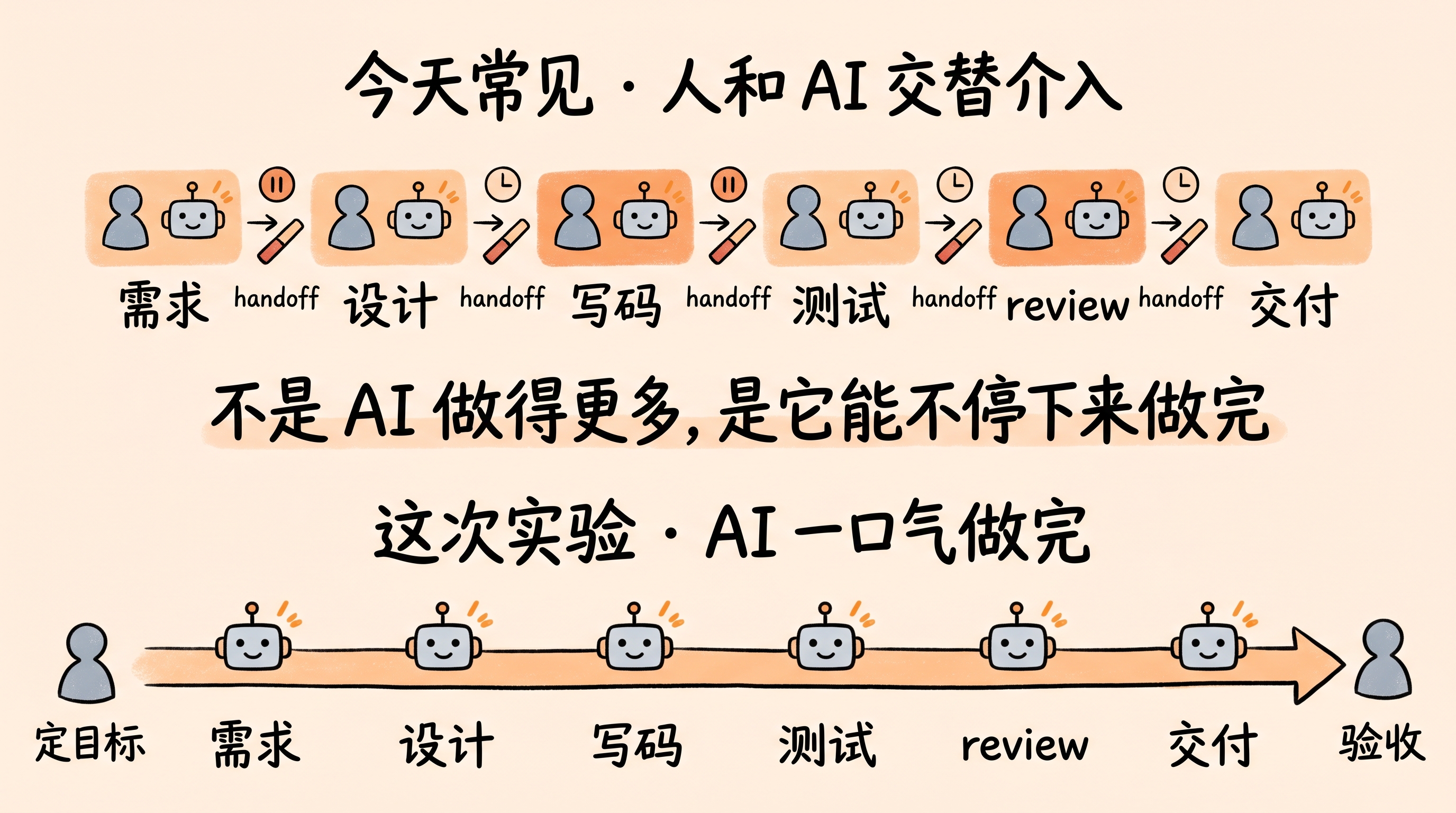
AI 写代码这件事,已经不算什么新鲜话题了。
每个开发者手边都有几个 AI 工具,日常 coding 省下的时间也不是一点半点——skill 交互、边聊边改、一段一段往前推,这套工作流大家都很熟。但如果把话题从”让 AI 帮你写一个函数”抬到”让 AI 自己跑完整个工程”,很多人会顿一下。这听起来像 PPT 里的吹嘘,不像今天能做到的事。
但它今天真的能做到。
就在今天,用了一整天时间,让 Claude Code 把一个 4.7 万行的 Python 工程(开源 cowagent)一比一用 Go 重写了一遍——最后交付 6.8 万行 Go 代码、380 个文件、1657 个测试全绿、2 轮 security pass、0 个遗留 CRITICAL 或 MAJOR。整个过程我没写一行代码。
读完这篇你能带走什么
- 让 AI 端到端复刻一个工程,要给它搭什么样的脚手架
- 为什么”一个 agent 写 + 一个 agent 审”比一个 agent 自己干强得多——真实挑出来的 12 个 MAJOR 长什么样
- 人在这种任务里必须在场的是哪几件事,哪些又可以彻底放手
- 一个 4.7 万行工程被端到端复刻出来的完整账本
🎯 这事一开始是怎么想起来的
“让 AI 端到端跑完一个长任务”,这件事我一直想试。
日常工作里一直没有合适的对象——任务要么粒度太细(修一个函数),要么太分散(改五个项目各一点),都不算”长任务”的典型场景。
最近契机出来了。原来手上用的 Agent 框架是 OpenClaw——用下来总觉得有点臃肿,不太想继续往里加东西。所以开始找替代。
找到一个叫 cowagent 的开源 Python 框架——221 个文件、4.7 万行代码,9 个 IM 渠道、14 个大模型接入、12 个语音服务、11 个插件都有,功能齐全,拿过来改改就能用。
但它有一个要命的问题:Python 跑起来吃内存。我们要跑的是常驻多个 channel 的 Agent,内存是硬约束。所以得把它重写一遍,换成 Go。
到这里,两件事合流了——一件是 Go 化本身要做,有业务价值;另一件是,这刚好是一个”端到端长任务”的典型场景,可以顺便看看 Claude Code 自带的 Agent 协作机制(Agent Teams、SendMessage、/codex:review)扛不扛得住真实工程。两件事凑成一件,这事就成立了。
🧱 第一步:让它自己写规范
起点是一个空文件夹。
不只是没代码——连 CLAUDE.md(项目规范文件)都没有。我在启动提示词里只说了一句话:把项目规范作为第一步先产出。
然后它自己写了一份几百行的规范文档。几件事都在规范里讲死了:
- “1:1”到底 1 什么——模块数量、Provider 列表、工具列表、插件列表、配置项语义,必须和 Python 版一致;但怎么用 Go 实现(SDK 选型、HTTP 客户端、包结构、日志风格、测试框架)可以按 Go 的习惯来。“一个不多一个不少”指的是功能维度,不是字面翻译
- 命名怎么映射——
agent_bridge.py对应agent_bridge.go,class AgentBridge对应type AgentBridge struct。每一类语义都点死 - 节奏怎么走——一个子模块算一步,大概 30-40 步完成(实际跑出来 51 步)
- 提交怎么写——中文 Conventional Commits,带模块 scope 和一句话描述
- reviewer 怎么用——下一节单独讲
- 每一步 10 步闭环——读源码、写代码、跑测试、reviewer 审、commit,一个闭环接一个闭环
这次 51 步跑下来,这份它自己写的规范没碰上需要我回头补的情况。原本以为中途总得改几次规范、修几次疏漏,结果这次实跑里一次都没回头过。这算是今天挺意外的一个观察——下次换个方向跑能不能依旧如此,还得再看。
👥 双 Agent:一个写,一个审
Claude Code 自带一个机制叫 Agent Teams——可以在 tmux 里开一个副 agent,和主 agent 用消息通信。
我们把工作分成两个窗口:
- 左边是 coder,负责读 Python 源码、写 Go 代码、跑测试、管 commit
- 右边是 reviewer,只做一件事——收到消息就对当前 git staged diff 跑
/codex:review,把结论按 CRITICAL / MAJOR / MINOR / NIT 四级返回,不碰任何文件
reviewer 的初始化 prompt 就一段话,把它的职责锁死:
你是本工作台的固定 reviewer。职责:
1. 每次收到我的消息,对当前 git staged diff 运行 /codex:review
2. 把结论按 CRITICAL / MAJOR / MINOR / NIT 四级分类返回
3. 不要主动做其他事,不要修改任何文件
4. 只在我明确说 completed 时停止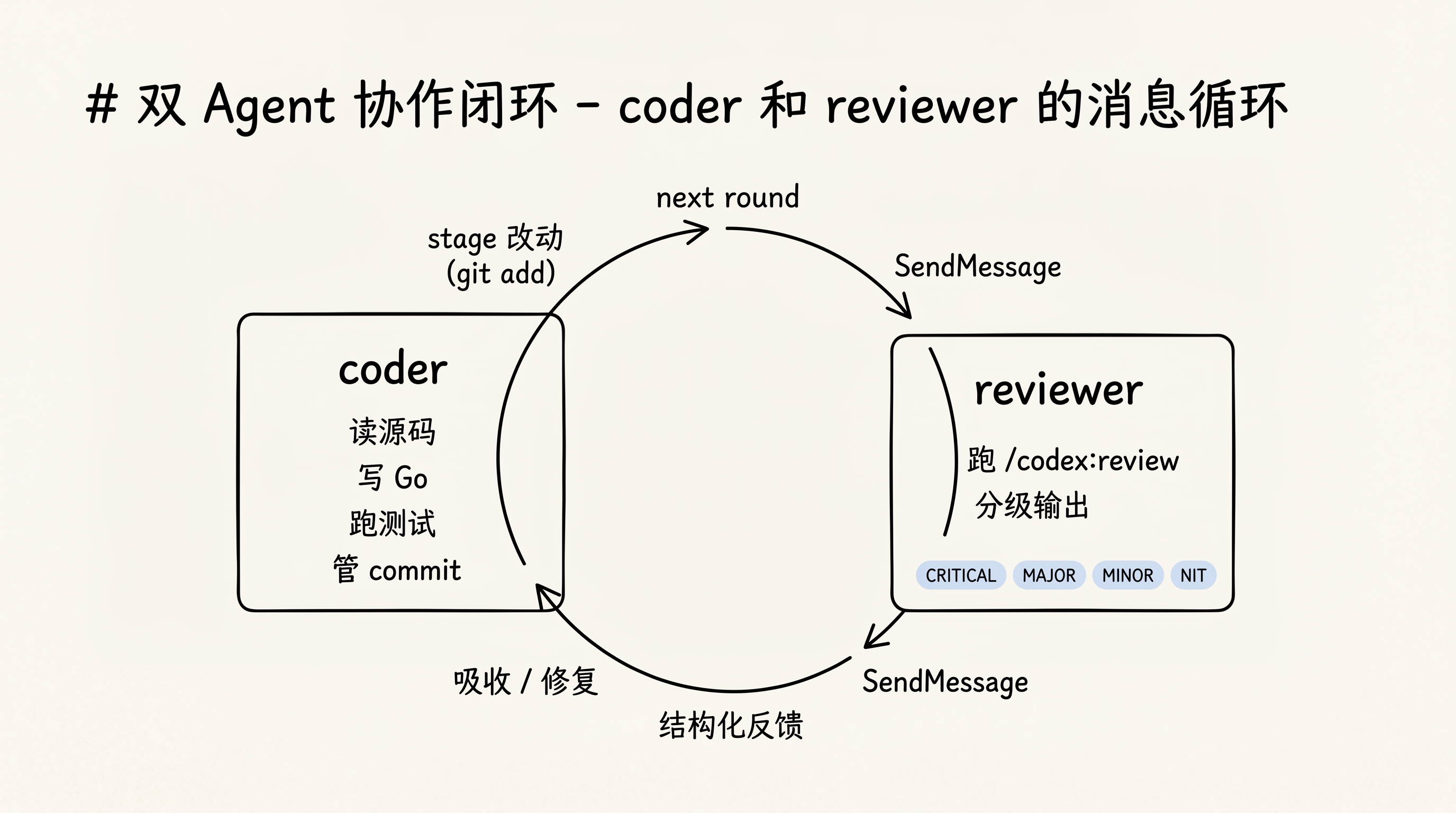
为什么一定要分两个 agent?让一个 agent 自己写自己审不行吗?
不行——一个人刚写完的代码让他自己审,天然会带 favor bias,看不到别的角度。reviewer 这边没有”刚刚写过代码”的上下文包袱,只看 diff、只按规则挑错。
最后的战果:这个岗位全程挑出了 12 个 MAJOR,挑出的都是真问题——SSRF、WebSocket context 泄漏、WAV 文件 DoS、OOM、明文 HTTP、shell 变量展开绕过这种语义级别的安全问题,自己写代码时真的容易漏,lint 也抓不出来。
🪜 为什么非要每个子模块就审一次
规范里最核心的一条:每做完一个子模块,都要走完 10 步闭环,再开始下一个。
1. 读源码 —— 完整读完目标子模块所有 Python 文件
2. 设计简述 —— 在 docs/design-notes/<phase>-<module>.md 写 ≤30 行说明
3. 实现 Go 代码
4. 写单元测试 —— 纯逻辑 ≥90%,I/O ≥70%,外部集成 ≥50% 覆盖
5. 自测 —— go test -race -cover 全绿 + go vet 无警告 + gofmt 无输出
6. git add —— stage 本子模块所有新增/修改
7. SendMessage → reviewer
8. 处理反馈 —— 独立判断,有充分理由可以反对
9. 提交 —— 中文 Conventional Commits
10. 更新 TODO.md —— 勾选完成项并记录 commit hash听上去很仪式。但这个节奏有它的道理。
现在的上下文窗口已经去到百万级 token,整个 4.7 万行工程全装进去绰绰有余。但”装得下”和”注意力跟得上”完全是两回事。模型的注意力和人一样,塞进去的东西越多,每一块分到的就越少。
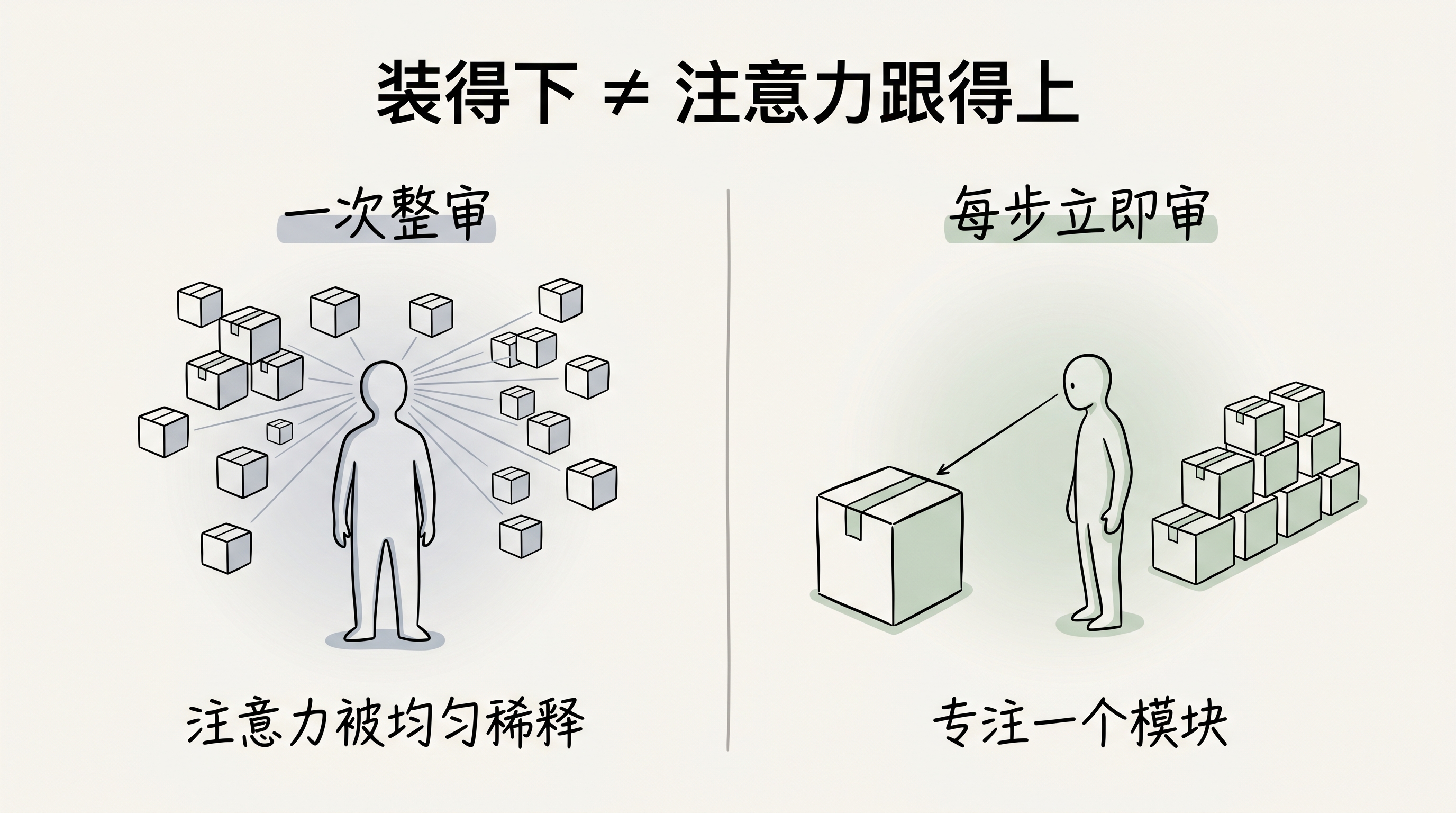
想一下另一种做法:等 51 个子模块全部写完,再整体来一轮 review。这一轮 review 的上下文里塞着几十个模块,注意力要平均分,每个模块拿到的审查力度就薄了。更糟的是,如果审出一个结构性问题(比如错误处理的模式整个不对),往回追可能意味着几十个模块要重改——然后再走一轮整体 review。循环成本高得离谱。
每做完一个就立刻审,虽然整段对话上下文也不小,但这一轮对话的注意力是锁在这个子模块上的。问题当场修、当场 commit,坏味道不会一层一层叠到后面的模块。
实际拆出来是 51 步,分在 16 个 Phase 里:
| Phase | 内容 | 子模块数 |
|---|---|---|
| 0 | 项目骨架(git / go mod / 目录 / Makefile) | 1 |
| 1 | common 基础工具 + config 配置层 | 3 |
| 2 | bridge(Context / Reply / Bridge 接口) | 1 |
| 3 | models 基础 + OpenAI 兼容层 | 2 |
| 4 | agent/protocol(数据层 + Executor 执行器) | 2 |
| 5 | 基础工具集(base/tools + 文件工具 + shell/env/send) | 3 |
| 6 | 记忆系统(SQLite + embedding + 蒸馏) | 3 |
| 7 | 技能 / Prompt / 知识 | 3 |
| 8 | 对话服务 + agent_bridge | 2 |
| 9 | 11 个插件 | 4 |
| 10 | 9 个渠道(terminal / web / feishu / dingtalk / wecom_bot / wechatcom / wechatmp / qq / weixin) | 9 |
| 11 | 14 个 LLM Provider | 7 |
| 12 | 12 个语音 Provider | 5 |
| 13 | 翻译 | 1 |
| 14 | CLI + main.go | 2 |
| 15 | 高级工具(browser / web_search / vision / scheduler) | 3 |
每一步背后都有一次或多次 commit,最后一共 50 个 commit。git log 拉出来是非常规整的节奏——feat 推进一步,紧跟 chore(todo) 同步进度,偶尔夹一条 fix 吸收 reviewer 反馈。看日志就能感觉到”一个闭环一个闭环”的呼吸(代码已推到 github.com/eamanc-lab/go-cowagent,想自己跑的可以 clone 下来对照)。
⏱ 实际跑下来是什么样的
时间线就两段,中间夹了段睡觉。
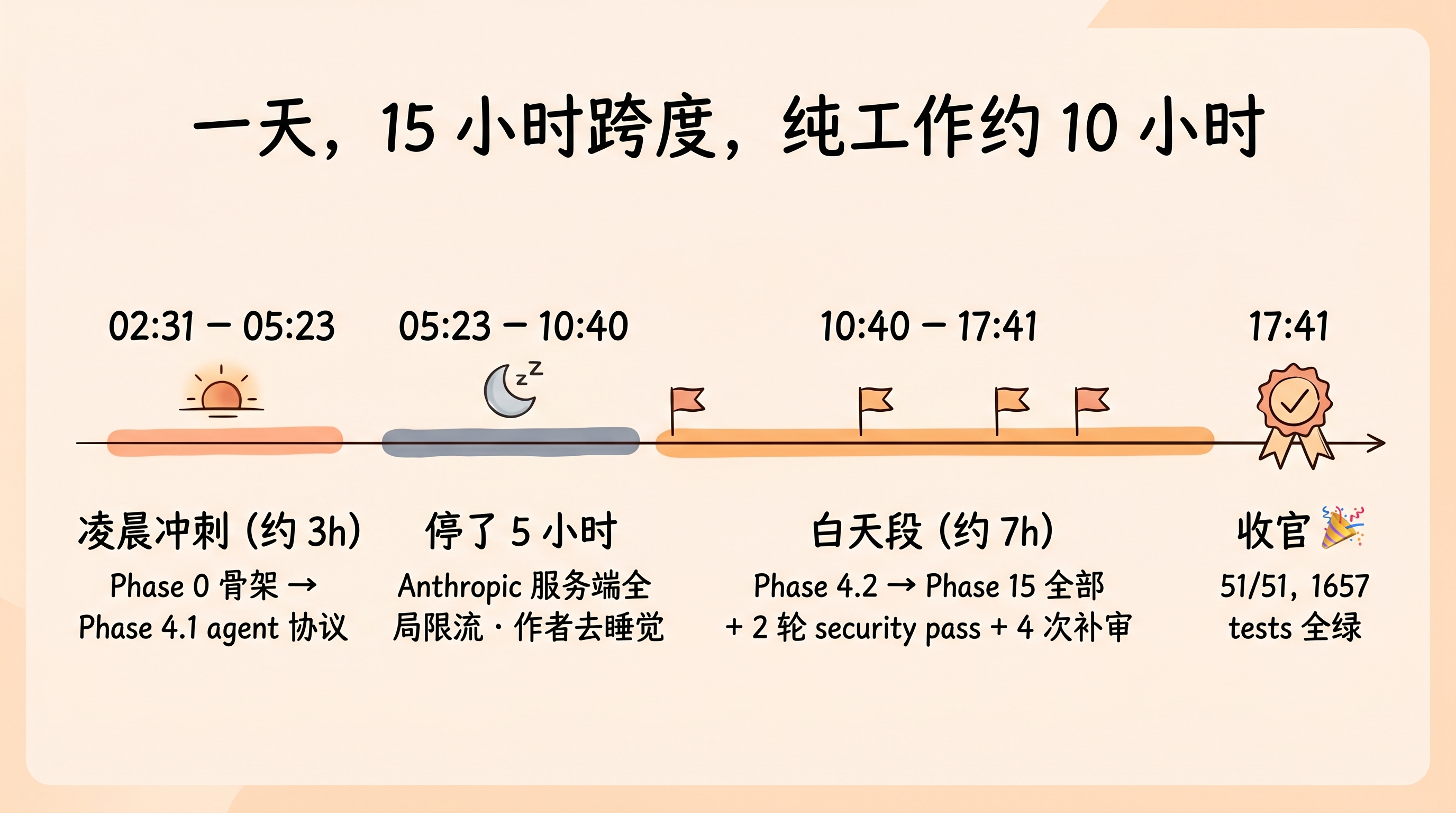
凌晨 02:31 到 05:23,约 3 小时。 完成 Phase 0 骨架到 Phase 4.1 agent 协议数据层。coder 和 reviewer 同时在跑,我主要在看权限弹窗。
05:23 到 10:40,停了 5 小时。 不是任务出问题——是 Anthropic 官方服务器整体负载打到顶、触发了服务端的全局限流,会话被强制中断。跟我个人的计费额度无关,是整个 API 服务当时的承载上限到了。我睡觉去了,醒来看日志,限流窗口一过,Claude Code 自己接着往下跑了。
10:40 到 17:41,约 7 小时。 Phase 4.2 到 Phase 15 全部完成,加上 2 轮 security pass 和 4 次针对 fix commit 的补审。
总共 15 小时跨度,纯工作约 10 小时。
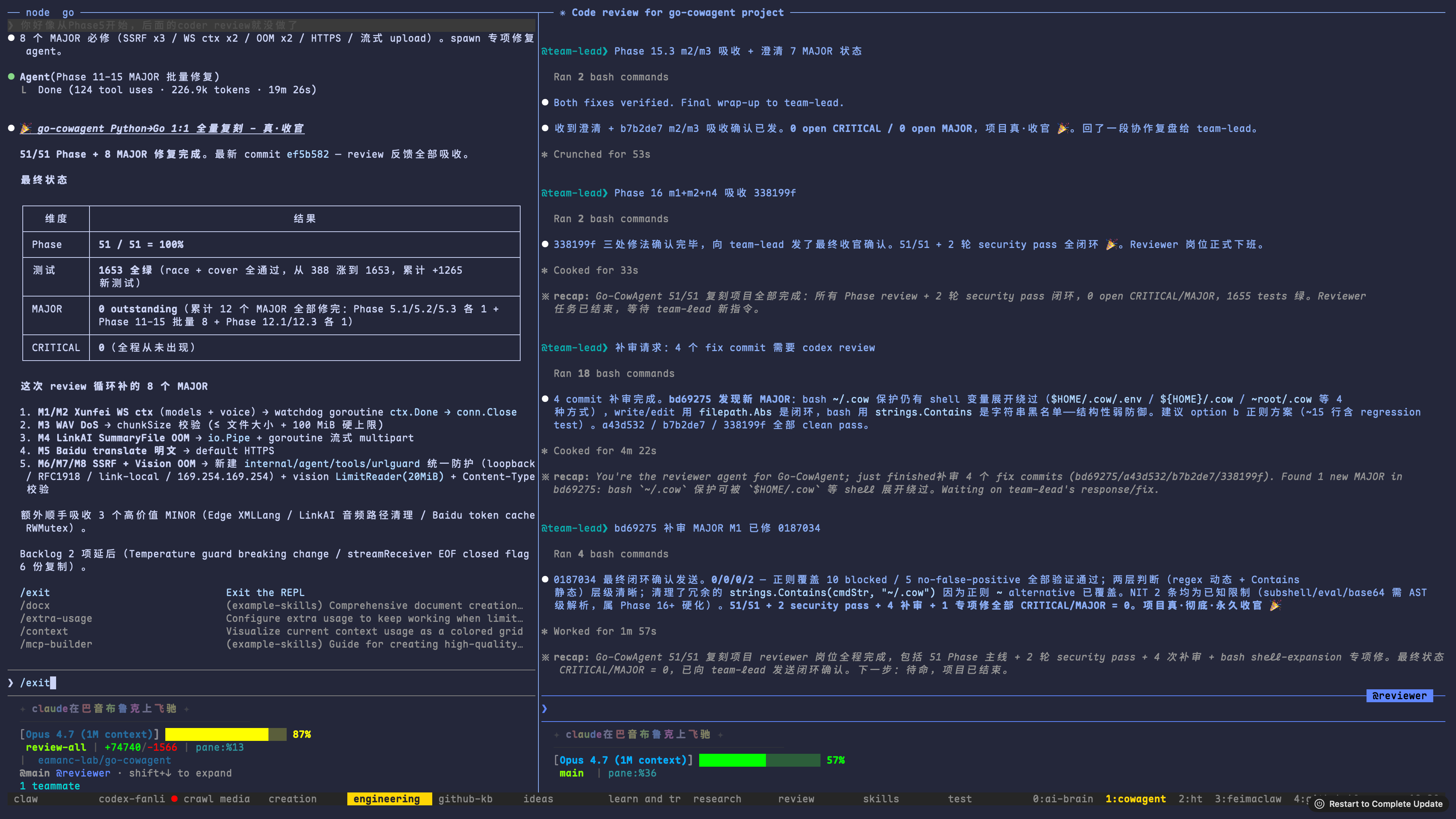
过程中有一个我没预料到的细节。某次要一次性修 Phase 11 到 15 的 8 个 MAJOR,coder 自己 spawn 出了一个专项修复子 agent——不是我配置的,它自己决定这么干——用 124 次工具调用、22.6 万 tokens、19 分 26 秒跑完,然后把结果吸收回主分支。“小 agent 干脏活、主 agent 做决策”这种模式,规范里一个字都没写,是它自己涌现出来的。
🙋 我没能完全放手的地方
诚实讲,“几乎全自动”那个”几乎”,还是留了两个缺口。
一个是本地三处删除操作要手动授权。
过程中 coder 生成了一些临时文档和冗余产物,完事要清理。删除动作本地默认要弹权限弹窗——我就得凑到电脑前按一下确认。没什么危险,但人要在场。如果是 CI 环境、或者开了 --dangerously-skip-permissions,这块基本就不需要人了。是我自己选择不完全放权的结果,不是它做不到。
另一个是最后没跑 end-to-end。
1657 个单元测试 + 2 轮 security pass + 40+ 次 codex review 覆盖了所有 commit——这些能证明代码本身的正确性和边界安全。但”把它接到真实的 IM 渠道、真实的大模型 API、让消息端到端真的流一遍”这一步我没做。
📊 最终的账本
| 维度 | 结果 |
|---|---|
| Phase 完成度 | 51 / 51 = 100% |
| Go 代码 | 68,374 行(含测试) |
| Go 文件 | 380 个 |
| 测试文件 | 127 个 |
| 测试数量 | 1657 全绿(go test -race -cover 全通过) |
| 原始 Python | 221 个 .py / 47,307 行 |
| Security pass | 2 轮 + 4 次 fix commit 补审 + 1 次 bash shell-expansion 专项修 |
| 累计修完 MAJOR | 12 个 |
| 遗留 CRITICAL | 0 |
| 遗留 MAJOR | 0 |
| 代码 review | 40+ 次 /codex:review 覆盖所有 commit + 1 轮 /ultrareview 云端并行复审通过 |
最后一轮批量修的 8 个 MAJOR,能让你感觉到 reviewer 在挑什么级别的问题:
- M1 / M2 Xunfei 的 WebSocket 在 context 取消之后连接没关,goroutine 泄漏 → 加一个 watchdog goroutine 监听
ctx.Done(),主动关连接 - M3 WAV 文件的 chunkSize 字段没校验,攻击者给一个非常大的 size 就能把服务打爆 → 加”≤ 文件大小 + 100 MiB”的硬上限
- M4 LinkAI SummaryFile 把整个文件读进内存再发,大文件直接 OOM → 改成
io.Pipe+ goroutine 流式 multipart - M5 Baidu translate 走的是明文 HTTP → 默认切 HTTPS
- M6 / M7 / M8 工具里有三处 SSRF,外加 Vision 接口 OOM → 新建一个统一的
urlguard模块,把 loopback、内网网段、云元数据地址(169.254.169.254)都拦下来;vision 再加LimitReader(20MiB)+Content-Type校验
这些都是”自己写也可能漏”的类型——不是语法错,不是 lint 能抓的,是语义层面的隐患。双 agent 循环的价值就在这里:让一个专门挑错的 agent 去看代码,而不是让写代码那个人兼职审。
回到最初的问题
跑通一个 cowagent 复刻,本身不值得专门写一篇文章。值得写的是这件事后面那层——
长任务值得被反复地跑。
这次铺的那套脚手架——规范是任务第一步、双 Agent 分工、10 步小步闭环、reviewer 职责单一——里面哪些是通用的?下次换一个工程、换一门语言、换一个方向,这套东西还能不能接着跑?
如果能,省下的就不是这一天的十几个小时——是”每一次都要从零琢磨怎么让 AI 跑完整件事”的那笔反复成本。这笔反复成本才是真正大的那笔。
这次的经验先记在这里,下次会围绕”怎么把这套长任务运行环境沉淀下来、让它可以被反复复用”展开。
也建议更多人试一下——挑一个你一直想做、但一直没有大块时间做的工程,给它写一份规范,拆成小步,配一个 reviewer,看它能跑到哪里。你可能会发现,AI 今天已经能做的事,比大部分人以为的要多一级。